SurveyX:中国人民大学等推出的自动化学术综述生成系统
SurveyX简介
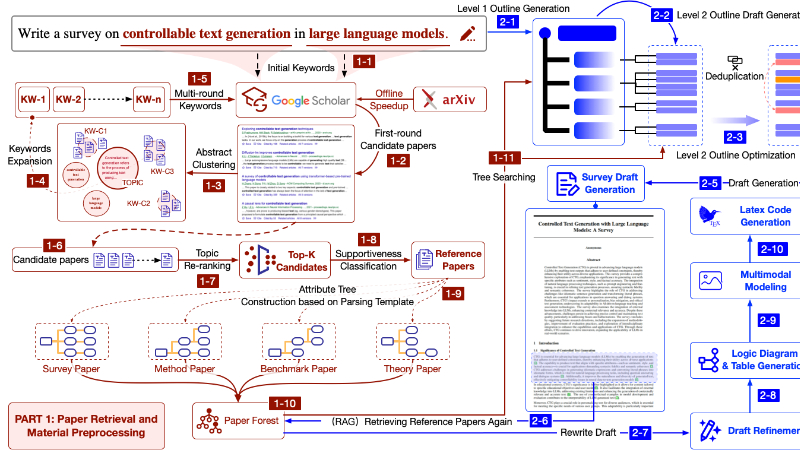
SurveyX是由中国人民大学、东北大学和悉尼大学等机构的研究团队共同开发的自动化学术综述生成系统。该系统利用大型语言模型(LLMs)的强大能力,通过创新的两阶段流程——准备阶段和生成阶段——高效生成高质量的学术综述。在准备阶段,SurveyX通过高效的文献检索算法和独特的AttributeTree预处理方法,精准筛选并提取关键信息;生成阶段则结合大纲优化、正文生成和后处理优化模块,确保综述结构清晰、内容准确且富有逻辑性。实验表明,SurveyX在内容质量和引用质量上显著优于现有系统,接近人类专家水平,为学术研究提供了有力支持。
SurveyX主要功能
-
高效文献检索与筛选:SurveyX能够通过关键词扩展算法和两步过滤方法,从离线和在线数据源中广泛检索并精准筛选出与主题高度相关的文献,确保综述的时效性和全面性。
-
文献预处理与信息提取:采用AttributeTree方法,将文献的关键信息提取并构建成属性树,优化文献信息密度,提升LLMs对文献的理解和上下文窗口的利用效率。
-
高质量综述生成:分为大纲生成、正文生成和后处理优化三个模块。通过“Outline Optimization”方法生成逻辑严谨的大纲,并结合提示(hints)生成连贯的正文内容,最终通过重写模块和图表生成模块优化引用质量和丰富表现形式。
-
多模态呈现:在生成的综述中加入图表和逻辑图,丰富综述的表现形式,提升可读性和信息传达效率。
-
系统性评估:提供扩展的评估框架,涵盖内容质量、引用质量和文献相关性等多个维度,为后续研究提供标准化的评估方法。
SurveyX技术原理
-
检索增强生成(Retrieval-Augmented Generation, RAG):通过检索外部文献信息,弥补LLMs内部知识库的不足,确保生成内容的准确性和时效性。检索模块结合离线数据库和在线爬虫系统,实现文献的广泛覆盖和精准筛选。
-
AttributeTree预处理方法:将文献内容转化为属性树结构,提取关键信息并构建属性森林,优化LLMs对文献的理解和上下文窗口的利用,从而提升生成综述的质量。
-
分阶段生成策略:将综述生成分为准备和生成两个阶段。准备阶段负责文献检索和预处理;生成阶段进一步细分为大纲生成、正文生成和后处理优化,逐步构建高质量的综述内容。
-
基于提示(Hints)的生成机制:在大纲和正文生成阶段,LLMs根据文献的属性树生成提示(hints),指导生成逻辑严谨的大纲和连贯的正文内容,提升生成结果的结构化程度。
-
多模态内容生成:结合多模态大语言模型(MLLMs)和信息提取模板,生成图表和逻辑图,丰富综述的表现形式,提升信息传达的效率和可读性。
-
后处理优化:通过RAG重写模块优化引用准确性和内容连贯性,并通过图表生成模块进一步提升综述的表现力,确保生成结果的质量接近人类专家水平。
SurveyX应用场景
-
学术研究:快速生成特定领域的综述文章,帮助研究人员全面了解研究现状,节省文献调研时间。
-
文献整理:自动整理大量文献,提取关键信息,辅助研究人员进行文献管理和知识梳理。
-
课程准备:为教师快速生成课程相关的学术综述,提供教学素材,丰富课程内容。
-
行业报告:生成特定行业的技术综述或趋势分析,为从业者提供决策支持和市场洞察。
-
科研项目申请:帮助研究人员快速撰写项目申请书中的文献综述部分,提升申请质量。
-
学术写作辅助:为学术写作提供结构化框架和内容参考,辅助撰写高质量的学术论文或报告。
SurveyX项目入口
- 项目主页:https://www.surveyx.cn/
- GitHub代码库:https://github.com/IAAR-Shanghai/SurveyX
- HuggingFace:https://huggingface.co/papers/2502.14776
- arXiv技术论文:https://arxiv.org/pdf/2502.14776
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号