IndexTTS:B 站推出的零样本文本转语音系统
IndexTTS简介
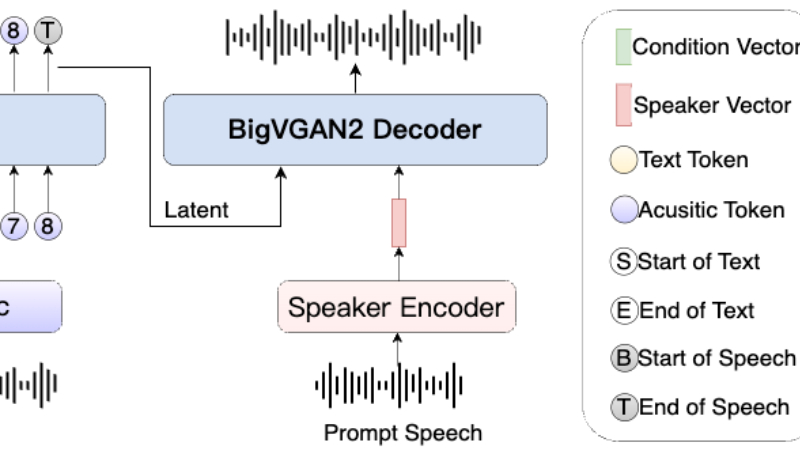
IndexTTS是由哔哩哔哩人工智能平台部开发的一款工业级可控且高效的零样本文本到语音(TTS)系统。该系统基于大型语言模型(LLM),结合了XTTS和Tortoise模型,并针对中文场景进行了多项创新改进。它采用字符与拼音混合建模方法,有效解决了多音字和长尾字符的发音控制问题;同时引入基于Conformer的语音条件编码器和BigVGAN2解码器,显著提升了语音克隆的自然性和音色相似度。IndexTTS在自然性、内容一致性和零样本语音克隆能力上超越了现有的开源TTS系统,具有更简单的训练流程、更高的可控性和更快的推理速度,适用于多种应用场景。
IndexTTS主要功能
-
多语言支持:支持中文和英文的高质量语音合成,未来计划扩展到更多语言。
-
零样本语音克隆:能够根据少量语音样本生成与原说话者高度相似的语音,无需大量数据训练。
-
多音字纠正:通过字符与拼音混合建模,用户可以手动输入拼音纠正多音字的发音,提升语音合成的准确性。
-
副语言表达:未来计划支持超现实副语言表达,如笑声、犹豫和惊讶等,增强语音的情感和自然度。
-
实时语音合成:采用高效的混合架构和解码器,支持实时语音合成,适用于流式交互场景。
-
情感复制:通过强化学习等技术增强情感表达能力,使合成语音更具感染力。
IndexTTS技术原理
-
混合建模方法:
-
结合中文字符和拼音建模,解决多音字和长尾字符的发音问题。
-
使用BPE(Byte Pair Encoding)文本标记器,支持多语言扩展和端到端学习。
-
-
语音编解码器:
-
采用FSQ(Finite Scalar Quantization)替代VQ(Vector Quantization),优化代码书利用率,避免代码书崩溃问题。
-
使用单码本编解码器,结合低比特率配置,平衡性能和生成质量。
-
-
大型语言模型(LLM):
-
基于解码器仅Transformer架构,生成高质量的音频梅尔标记。
-
使用Conformer条件编码器替代传统Transformer,增强音色相似性和训练稳定性。
-
-
语音解码器:
-
采用BigVGAN2解码器,直接将SpeechLLM输出转换为波形,提高推理速度和音质。
-
支持基于说话者嵌入的条件生成,确保语音合成的音色一致性。
-
-
数据驱动的训练:
-
使用大规模中英双语数据(34,000小时)进行训练,提升模型的泛化能力和稳定性。
-
通过ASR生成伪标签,并结合语义和语音停顿添加标点符号,增强训练数据的质量。
-
-
优化的推理流程:
-
通过简化输入预处理和高效的模型架构,降低推理延迟,适用于实时应用场景。
-
支持多种输入方式,包括纯文本、带拼音的混合文本等,提升系统的灵活性和可控性。
-
IndexTTS应用场景
-
视频创作配音:为短视频、动画、广告等快速生成自然语音配音,节省人工录制时间。
-
智能客服:提供多语言、个性化语音交互服务,增强用户体验。
-
有声读物:将文本内容转化为生动的语音朗读,满足不同用户的阅读需求。
-
教育领域:生成教学语音,辅助语言学习或为视障人士提供语音教材。
-
游戏配音:实时生成角色语音,提升游戏的沉浸感和互动性。
-
语音播报:用于新闻、天气、交通等信息播报,提升信息传递的效率和准确性。
IndexTTS项目入口
- Github代码库:https://github.com/index-tts/index-tts
- arXiv技术论文:https://arxiv.org/pdf/2502.05512
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号