WarriorCoder简介
WarriorCoder是由华南理工大学计算机科学与工程学院和微软团队共同开发的代码生成语言模型。该方法通过构建一个“专家之战”的竞技场,让多个领先的代码生成大语言模型(LLMs)相互挑战,由公正的裁判模型评估结果。WarriorCoder不依赖于现有的数据集或专有的LLMs,而是从头开始生成高质量的训练数据,整合了所有参赛专家模型的优势。实验表明,WarriorCoder在多个代码生成基准测试中达到了新的最高水平,显著优于其他开源模型,并且无需依赖专有LLMs的数据。这一成果为代码生成领域的模型训练提供了一种低成本、高效率的新思路。
WarriorCoder主要功能
-
生成高质量代码生成训练数据:WarriorCoder通过专家模型之间的竞争和评估,从头开始生成高质量的代码指令和响应数据,无需依赖现有的数据集或专有模型的标注。
-
提升代码生成模型的性能:通过整合多个专家模型的优势,WarriorCoder能够显著提升目标模型在代码生成、代码推理和库使用等任务上的性能,达到新的最高水平。
-
降低数据收集成本:该方法无需人工标注或专有模型生成的指令,能够以低成本生成多样化的训练数据,提高数据的独立性和泛化能力。
-
增强模型的泛化能力:通过竞争生成的训练数据覆盖多种任务类型,使目标模型在不同代码生成场景中表现出色,具备更好的泛化能力。
WarriorCoder技术原理
-
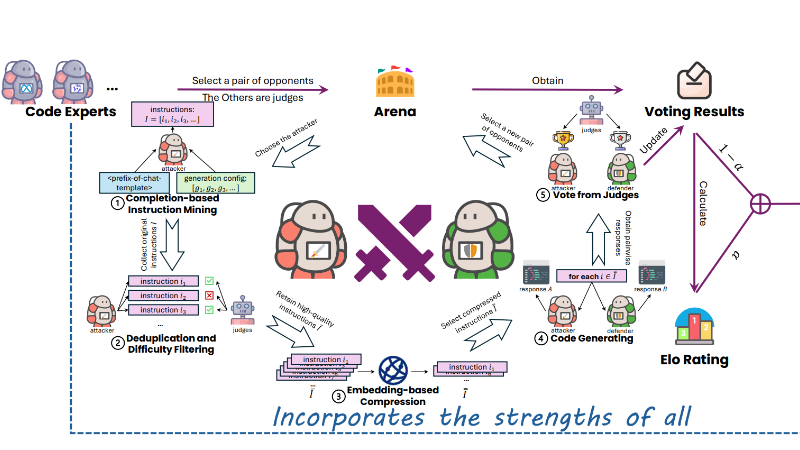
专家模型竞争框架:构建一个竞技场,让多个专家代码生成模型(LLMs)相互挑战。每轮比赛中,一对模型作为攻击者和防守者,其余模型作为裁判,评估双方的表现。
-
指令挖掘与筛选:使用基于补全的方法挖掘攻击者模型已掌握的指令,通过去重和难度筛选保留高质量指令,避免数据的重复性和模糊性。
-
胜负决策与评分:结合裁判模型的投票结果和Elo评分系统,综合评估模型在每轮比赛中的表现,平衡局部表现和全局一致性,选择最佳响应作为训练数据。
-
目标模型训练:使用从竞争中生成的高质量指令和响应对目标模型进行微调,使其吸收所有专家模型的优势,提升整体性能。
-
多样化数据生成:通过专家模型之间的竞争,生成覆盖多种任务类型的训练数据,确保目标模型在不同代码生成任务中表现出色。
WarriorCoder应用场景
-
代码生成:自动生成高质量的编程代码,帮助开发者快速实现功能模块,减少手动编写代码的工作量,提升开发效率。
-
代码调试与优化:辅助开发者识别代码中的错误或性能瓶颈,并提供优化建议,提升代码质量和运行效率。
-
代码理解与分析:帮助开发者理解复杂代码的功能和逻辑,解释代码执行过程,便于代码维护和学习。
-
编程教学辅助:为编程学习者提供示例代码和解题思路,帮助他们更好地掌握编程语言和算法,提升学习效果。
-
自动化测试:生成测试用例代码,帮助开发者快速验证程序的功能是否符合预期,提高测试覆盖率。
-
跨语言代码转换:将一种编程语言的代码转换为另一种语言的代码,方便开发者在不同语言环境中迁移和复用代码。
WarriorCoder项目入口
- arXiv技术论文:https://arxiv.org/pdf/2412.17395
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号