SepLLM:华为等推出的加速大语言模型的高效框架
SepLLM简介
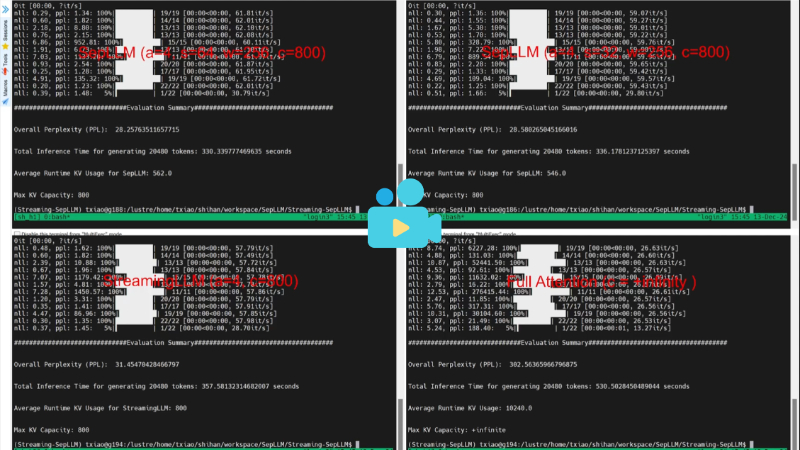
SepLLM是由华为诺亚方舟实验室、香港大学、KAUST卓越生成人工智能中心和马普智能系统研究所共同开发的一种高效语言模型框架。该框架通过将文本段落信息压缩到分隔符(如标点符号)中,显著减少了大型语言模型(LLMs)在推理过程中的计算需求和内存占用。SepLLM利用一种数据依赖的稀疏注意力机制,仅保留初始、邻近和分隔符token,从而实现高效的信息检索和加速。实验表明,SepLLM在多种任务中表现出色,能在保持与传统Transformer相当性能的同时,将KV缓存减少50%以上,并有效处理长达400万token的序列。其开发团队还提供了公开的代码实现,支持多节点分布式训练和多种加速操作,为高效语言模型的开发和应用提供了新的思路。
SepLLM主要功能
-
加速语言模型推理:通过压缩文本段落信息到分隔符(如标点符号)中,减少冗余token的计算,显著降低KV缓存占用,从而加快推理速度。
-
降低计算成本和内存占用:在保持模型性能的同时,大幅减少计算量(FLOPs)和内存使用,尤其适用于处理长文本和大规模模型。
-
支持流式应用:针对无限长度的输入(如多轮对话),SepLLM通过动态管理KV缓存,能够高效处理长达数百万甚至数千万token的序列。
-
兼容多种训练场景:适用于训练自由、从头开始训练和后训练等多种场景,减少了训练和推理之间的性能差异。
-
支持多节点分布式训练:提供高效的训练加速模块,支持多种融合操作符,提升了训练效率和可扩展性。
SepLLM技术原理
-
分隔符信息压缩:通过分析Transformer模型的注意力模式,发现分隔符token(如逗号、句号等)在注意力分数上占据主导地位。SepLLM将文本段落信息压缩到这些分隔符token中,使得模型在推理时只需关注分隔符即可获取关键信息。
-
稀疏注意力机制:采用数据依赖的稀疏注意力机制,仅保留初始token、邻近token和分隔符token的注意力计算,忽略其他冗余token,从而减少计算复杂度。
-
动态KV缓存管理:在流式应用中,SepLLM通过维护四个缓存块(初始缓存、分隔符缓存、过去窗口缓存和局部窗口缓存),动态管理KV缓存的存储和更新,避免内存溢出。
-
硬件高效训练加速:通过实现高效的计算内核(如Sep-Attention模块),SepLLM在训练阶段减少了计算量和训练时间,同时保持了与传统Transformer相当的性能。
-
通用近似能力:从理论上证明了SepLLM具有通用近似能力,能够逼近任意序列到序列的连续函数,确保其在不同任务中的适用性。
SepLLM应用场景
-
长文本处理:高效处理长篇小说、学术论文等长文本生成任务,减少内存占用和推理时间。
-
多轮对话系统:支持无限长度的多轮对话,适用于智能客服、虚拟助手等场景。
-
数学问题求解:在数学推理和多步计算任务中表现出色,如GSM8K等数学问题求解基准。
-
多学科知识问答:适用于跨学科知识推理任务,如MMLU等基准测试,提供准确的知识检索。
-
实时文本生成:在流式文本生成任务中,如新闻直播、实时翻译等场景,能够快速生成高质量文本。
-
大规模模型推理优化:为大型语言模型(如Llama、Pythia等)提供推理加速,降低计算成本,提升效率。
SepLLM项目入口
- 项目主页:https://sepllm.github.io/
- Github代码库:https://github.com/HKUDS/SepLLM
- arXiv技术论文:https://arxiv.org/pdf/2412.12094
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号