Avat3r:生成高质量且可动画化的 3D 头部头像
Avat3r简介
Avat3r 是由慕尼黑工业大学(Technical University of Munich)和 Meta Reality Labs Pittsburgh 的研究团队共同开发的一种新型 3D 头部头像生成技术。它能够从少量输入图像(如四张)快速生成高质量且可动画化的 3D 头部头像,显著降低了传统方法对复杂设备和优化过程的依赖。通过结合大型重建模型和预训练的基础模型 DUSt3R 与 Sapiens,Avat3r 实现了高效的稀疏 3D 重建和面部动画化,并通过创新的交叉注意力机制赋予头像生动的表情变化。该技术不仅在多视角和单视角输入场景中表现出色,还具备出色的泛化能力,能够处理来自不同数据源的图像,甚至包括古董半身像或 AI 生成的图像。Avat3r 的开发为 3D 头像的快速生成和动画化开辟了新的可能性,有望广泛应用于影视制作、虚拟现实、个性化游戏和数字教育等领域。
Avat3r主要功能
-
从少量图像生成高质量 3D 头部头像:Avat3r 能够仅从几张输入图像(如四张)快速生成高保真、可动画化的 3D 头部头像,无需复杂的多视角捕捉设备或优化过程。
-
零样本面部动画化:该技术能够在没有目标人物表情数据的情况下,通过预训练的表情代码实现逼真的面部动画效果,支持任意表情的生成。
-
快速生成与实时渲染:Avat3r 的整个生成流程仅需几分钟,且能够在消费级 GPU 上运行,支持实时渲染和交互,适合实际应用场景。
-
鲁棒性与泛化能力:Avat3r 能够处理输入图像的不一致性(如表情变化、视角不一致等),并适用于多种数据源,包括智能手机拍摄的图像、单张照片,甚至古董半身像或 AI 生成的图像。
-
支持多场景应用:生成的 3D 头像可用于多种领域,如影视制作、虚拟现实、个性化游戏、数字教育等,具有广泛的应用前景。
Avat3r技术原理
-
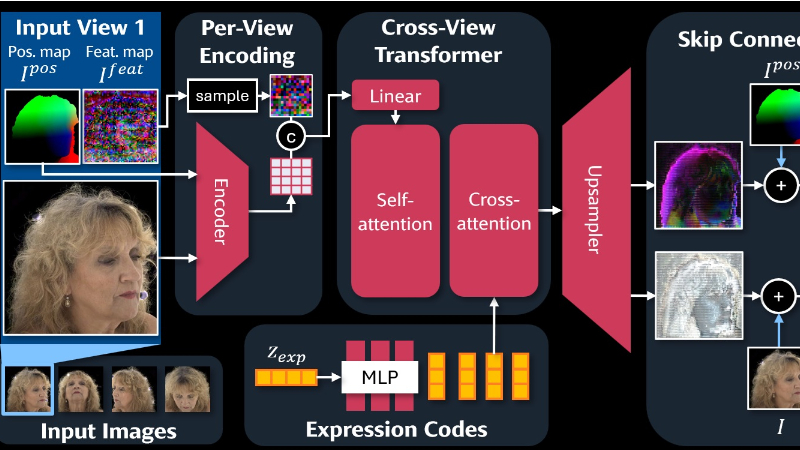
基于高斯分布的 3D 重建:Avat3r 使用 Vision Transformer 架构,预测每个输入图像像素的 3D 高斯分布(包括位置、尺度、旋转、颜色和透明度)。这些高斯分布组合成一个完整的 3D 头部模型,支持从任意视角的渲染。
-
预训练基础模型的集成
-
DUSt3R:用于生成输入图像的位置图,为 3D 高斯分布提供初始位置,增强几何对齐能力。
-
Sapiens:提供丰富的语义特征图,简化视图匹配任务,提升重建的细节和锐度。
-
-
交叉注意力机制实现动画化:通过简单的交叉注意力机制,将表情代码与图像特征相结合,使 3D 头像能够根据预定义的表情代码生成逼真的面部动画。
-
多视角和时序不一致性的处理:在训练过程中,模型输入不同时间步的图像(不同表情或视角),使其具备处理输入不一致性的能力,增强了模型的鲁棒性。
-
高效的训练与优化:使用 Ava256 数据集进行训练,结合 L1 损失、SSIM、LPIPS 等多种损失函数,优化模型的几何精度和视觉效果。同时,通过 k-farthest 视角采样和时序采样策略,提升训练效率和泛化能力。
-
单图像输入的扩展性:通过预训练的 3D GAN 将单张图像提升到 3D,再利用 Avat3r 进行动画化,进一步扩展了模型的应用范围。
Avat3r应用场景
-
影视制作:快速生成高质量的 3D 头像,用于虚拟角色制作,节省传统特效制作的时间和成本。
-
虚拟现实与增强现实:实时生成逼真的虚拟头像,提升用户在 VR/AR 环境中的沉浸感和交互体验。
-
个性化游戏:根据玩家提供的照片生成个性化的游戏角色头像,增强游戏的个性化和趣味性。
-
远程协作与虚拟会议:利用手机拍摄的图像生成逼真头像,用于远程协作工具中,提升沟通的自然感和真实感。
-
数字教育:创建虚拟教师或学习伙伴的 3D 头像,提升在线教育的互动性和吸引力。
-
社交媒体与娱乐:为用户提供个性化头像生成工具,支持动态表情和互动效果,丰富社交媒体和娱乐内容。
Avat3r项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号