AudioX:香港科技大学联合月之暗面推出的多模态音频生成框架
AudioX简介
AudioX 是由香港科技大学和月之暗面联合开发的多模态音频生成框架,旨在通过统一的模型架构实现从文本、视频、图像等多种输入模态生成高质量的音频和音乐。该框架采用基于扩散 Transformer(DiT)的技术,并结合多模态掩码训练策略,显著提升了跨模态表示学习的鲁棒性。开发团队还构建了两个大规模多模态数据集,以解决高质量训练数据稀缺的问题。AudioX 在多种音频生成任务中展现出卓越的性能,不仅能够生成高质量的音频和音乐,还具备强大的多模态输入处理能力和泛化能力,为多模态音频生成领域带来了新的突破。
AudioX主要功能
-
多模态音频生成:
-
支持从文本、视频、图像等多种输入模态生成高质量的音频和音乐。
-
可以灵活组合不同的输入模态,例如文本+视频、视频+音频等,以生成更符合需求的音频内容。
-
-
多种音频生成任务:
-
文本到音频(Text-to-Audio):根据文本描述生成对应的音频效果。
-
视频到音频(Video-to-Audio):根据视频内容生成匹配的音效或音乐。
-
图像到音频(Image-to-Audio):基于图像内容生成相关的音频。
-
音频修复(Audio Inpainting):对音频片段进行修复或填充缺失部分。
-
音乐续写(Music Completion):根据给定的音乐片段生成后续内容。
-
-
高质量音频生成:采用扩散模型(Diffusion Model)技术,生成高保真音频和音乐,确保音频的自然度和多样性。
-
自然语言控制:用户可以通过自然语言描述精确控制音频生成的内容,例如指定音乐风格、乐器、情绪等。
AudioX技术原理
-
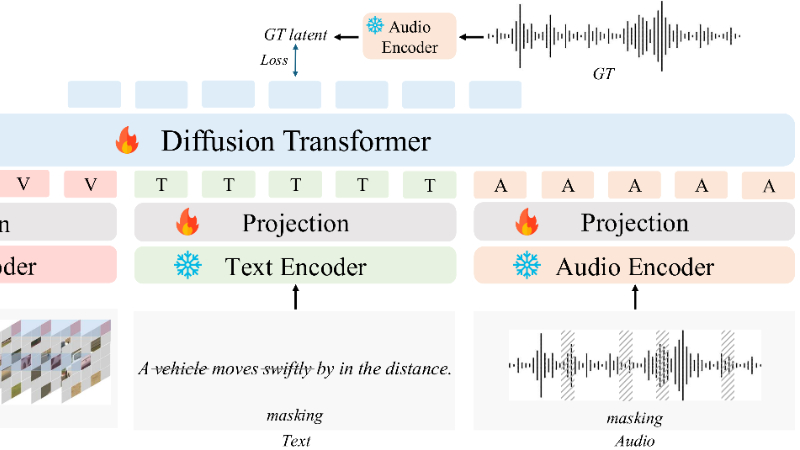
扩散Transformer(Diffusion Transformer, DiT):
-
基于扩散模型的生成框架,通过逐步去噪的过程生成高质量的音频和音乐。
-
结合Transformer架构,能够处理复杂的多模态输入,并生成连贯的音频输出。
-
-
多模态掩码训练策略:
-
在训练过程中,对输入的文本、视频和音频进行随机掩码处理,例如掩盖部分文本标记、视频帧或音频片段。
-
迫使模型学习从不完整的输入中恢复信息,从而增强跨模态表示的鲁棒性和泛化能力。
-
-
多模态特征融合:
-
使用专门的编码器分别处理视频、文本和音频输入,并将它们投影到统一的特征空间中。
-
通过特征融合,模型能够整合不同模态的信息,生成与输入条件一致的音频内容。
-
-
大规模多模态数据集:
-
开发团队构建了两个大规模多模态数据集(vggsound-caps和V2M-caps),包含丰富的文本描述和音乐描述。
-
这些数据集为模型提供了多样化的训练样本,解决了高质量多模态数据稀缺的问题。
-
-
自然语言控制与条件生成:
-
利用自然语言处理技术,将文本描述转化为条件输入,引导音频生成的方向。
-
模型可以根据文本描述的细节生成符合要求的音频,例如根据“快乐的钢琴音乐”生成相应的音乐片段。
-
AudioX应用场景
-
影视制作:根据视频内容自动生成背景音乐或音效,提升制作效率,降低创作成本。
-
游戏开发:实时生成与游戏场景匹配的音效和音乐,增强玩家的沉浸感。
-
社交媒体:为短视频、Vlog 等生成个性化音频或音乐,丰富内容表现力。
-
广告创意:快速生成符合广告主题的音乐和音效,提升广告的吸引力。
-
教育领域:根据教学内容生成音频辅助材料,如朗读、背景音乐等,提升学习体验。
-
虚拟现实(VR)和增强现实(AR):根据虚拟场景生成沉浸式音频,增强用户的临场感。
AudioX项目入口
- 项目主页:https://zeyuet.github.io/AudioX
- Github代码库:https://github.com/ZeyueT/AudioX
- arXiv技术论文:https://arxiv.org/pdf/2503.10522
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号