Block Diffusion简介
Block Diffusion 是由 Cornell Tech 和 Stanford University 等机构的研究团队开发的一种新型语言模型。它结合了自回归模型和扩散模型的优势,通过在块内进行扩散生成,并在块间利用自回归建模,实现了灵活长度的文本生成和高效的推理能力。该模型克服了传统扩散模型在固定长度生成和推理效率上的局限性,同时在语言建模基准测试中取得了新的最佳性能,展示了其在生成质量和效率上的显著提升。Block Diffusion 的开发为自然语言处理领域带来了新的技术突破,为未来的语言模型研究提供了新的方向。
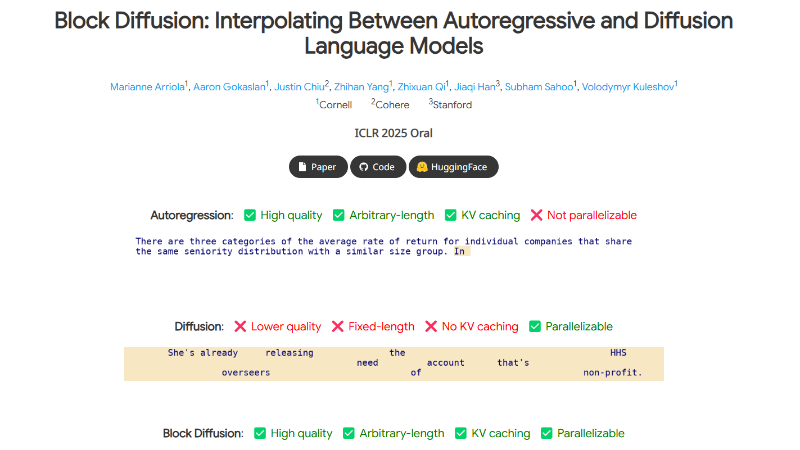
Block Diffusion主要功能
-
任意长度的文本生成:Block Diffusion 支持生成任意长度的文本序列,突破了传统扩散模型固定长度生成的限制。这使得模型能够生成更长的文本内容,例如长篇文章、故事或对话,而不仅限于训练时的上下文长度。
-
高效的推理能力:通过结合自回归建模和扩散生成的优势,Block Diffusion 在推理时可以利用块级并行化和缓存机制(如 KV 缓存),显著提高了生成效率,减少了计算资源的消耗。
-
高质量的文本生成:在语言建模基准测试中,Block Diffusion 实现了比传统扩散模型更低的困惑度(Perplexity),表明其生成的文本质量更高,更接近人类语言的自然性。
-
灵活性与可控性:由于其自回归和扩散相结合的特性,Block Diffusion 在生成过程中可以更好地控制文本的风格、内容和结构,同时支持多样化的生成任务,如续写、摘要和翻译等。
Block Diffusion技术原理
-
块级自回归建模:Block Diffusion 将文本序列划分为多个固定长度的块(block),并在块之间采用自回归建模。每个块的生成依赖于前面块的上下文信息,从而保留了自回归模型的顺序性和可控性。
-
块内扩散生成:在每个块内部,模型采用扩散生成机制。通过逐步去除噪声的方式生成文本,扩散模型能够利用并行化计算,提高生成效率并降低计算复杂度。
-
高效的训练算法:为了高效训练,Block Diffusion 提出了专门的算法,通过一次前向传递计算所有块的损失,同时利用向量化操作和优化的注意力机制,显著减少了训练时间。
-
低方差噪声调度:通过优化噪声调度策略,Block Diffusion 降低了扩散模型训练过程中的方差,提高了模型的稳定性和生成质量。这种调度策略避免了极端掩码率,确保模型在不同噪声水平下都能有效学习。
-
KV 缓存与并行采样:在推理阶段,Block Diffusion 利用 KV 缓存机制存储已生成块的上下文信息,避免重复计算。同时,模型支持块内的并行采样,进一步提高了生成速度。
Block Diffusion应用场景
-
长文本生成:用于生成长篇故事、小说或文章,突破固定长度限制,满足创作需求。
-
对话系统:提供高质量的对话生成,支持灵活长度的回复,提升聊天机器人的自然度和连贯性。
-
内容续写:根据给定的文本片段,生成后续内容,适用于创意写作或续写任务。
-
文本摘要与扩写:生成文本摘要或对短文本进行扩写,帮助用户快速获取信息或丰富内容。
-
多语言翻译:支持长文本的逐块翻译,提高翻译效率和质量,同时保持语义连贯性。
-
创意写作辅助:为作家或创作者提供灵感,生成创意文本片段或情节发展,激发创作思路。
Block Diffusion项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号