LVAS-Agent:能够为长视频生成高质量的同步音频
LVAS-Agent 简介
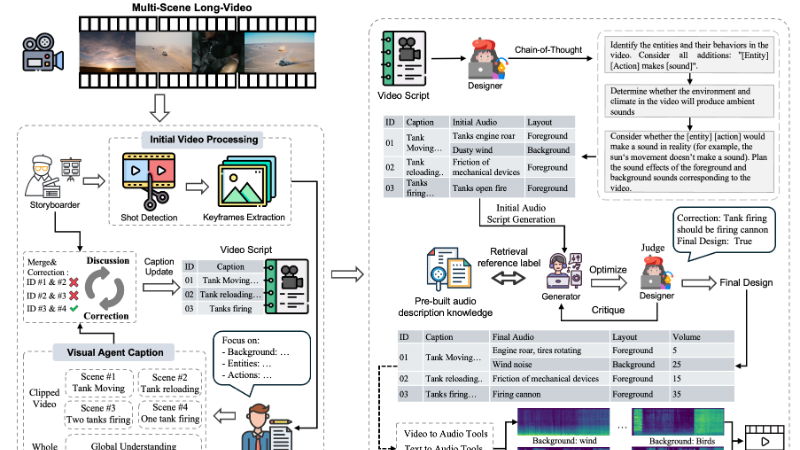
LVAS-Agent 是由香港科技大学(广州)和香港科技大学的研究团队开发的一种多智能体协作框架,专门用于长视频音频合成。该框架通过模拟专业配音工作流程,将长视频合成任务分解为场景分割、脚本生成、声音设计和音频合成四个阶段,并通过智能体之间的讨论修正和生成检索优化机制,有效解决了长视频音频合成中的语义连贯性、时间对齐和跨场景一致性问题。LVAS-Agent 的开发团队还发布了首个长视频音频合成基准数据集 LVAS-Bench,为相关研究提供了标准化的评估工具。实验结果表明,LVAS-Agent 在音频合成质量、语义对齐和时间对齐等方面均优于现有方法,显著提升了长视频音频合成的效果。
LVAS-Agent 主要功能
-
长视频音频合成:LVAS-Agent 能够为长视频生成高质量的同步音频,提升观众的沉浸感和叙事连贯性。
-
场景分割与脚本生成:自动将长视频分割为多个场景,并生成与视频内容对齐的详细脚本,为后续音频设计提供基础。
-
声音设计与标注:根据视频脚本,智能标注出前景对话和背景音效,确保音频与视频内容的语义一致性。
-
多层音频合成:结合神经文本到语音技术和扩散模型,生成高质量的多层音频(如前景音和背景音),并进行音量调整和混合。
-
语义与时间对齐:通过讨论修正机制和生成检索优化循环,确保音频与视频在语义和时间上的高度一致性。
LVAS-Agent 技术原理
-
多智能体协作架构:
-
通过定义不同角色(Storyboarder、Scriptwriter、Designer、Synthesizer)的职责,将复杂任务分解为多个子任务,实现高效协作。
-
不同智能体通过讨论修正机制和生成检索优化机制进行交互,提升合成效果。
-
-
场景分割与关键帧提取:
-
使用 HSV 色彩空间转换方法检测镜头切换,实现视频的粗略分割。
-
通过 K-Means 聚类算法提取关键帧,捕捉更多视觉信息,增强视频理解能力。
-
-
语义感知的脚本生成:
-
利用 CLIP 等视觉语言模型提取视频的语义特征,结合对话上下文分析生成时间对齐的音频脚本。
-
通过智能体间的协作,对脚本进行细化和优化,确保语义连贯性。
-
-
声音设计与音频合成:
-
采用链式思考(Chain-of-Thought)机制,逐步分析视频脚本中的主要动作声音、背景音效,并确保音频的连贯性。
-
使用检索增强生成(RAG)技术,结合预定义的音频标签知识库,生成高质量的音频。
-
-
生成检索优化循环:
-
Designer 智能体根据视频脚本生成初始声音设计,Synthesizer 智能体检索相关知识生成具体音频计划。
-
通过多次迭代反馈,优化音频合成计划,确保音频与视频在语义和时间上的高度一致性。
-
LVAS-Agent 应用场景
-
电影和电视剧配音:为影视作品生成高质量的背景音效和对话配音,提升观众的沉浸感,尤其适用于多场景切换的长视频内容。
-
动画制作:为动画视频自动生成与画面同步的音效和角色配音,提高制作效率,降低人工成本。
-
视频游戏音频设计:根据游戏中的动态场景和角色动作,实时生成匹配的音效和背景音乐,增强游戏的互动性和沉浸感。
-
教育视频制作:为教育视频添加生动的音效和旁白,使内容更加吸引学生,提升学习效果。
-
广告视频配音:快速生成与广告画面匹配的音频,满足广告制作中对音频质量和语义一致性的高要求。
-
虚拟现实(VR)和增强现实(AR)内容:为 VR 和 AR 应用生成沉浸式的音频环境,增强用户体验的真实感。
LVAS-Agent 项目入口
- 项目主页:https://lvas-agent.github.io/
- GitHub代码库:https://github.com/ZYH-Lightyear/LVAS
- arXiv研究论文:https://arxiv.org/abs/2503.10719
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号