Multi-Speaker:全球首个高分辨率多说话人声分离模型
Multi-Speaker简介
Multi-Speaker 是由 AudioShake 团队开发的全球首个高分辨率多说话人声分离模型。该模型能够将音频中的多个说话人精准分离到不同轨道,支持高采样率,适合广播级音频质量,并可处理长达数小时的录音。它适用于影视制作、播客编辑、字幕转录等多种场景,能够有效解决传统音频工具在处理重叠语音时的难题。
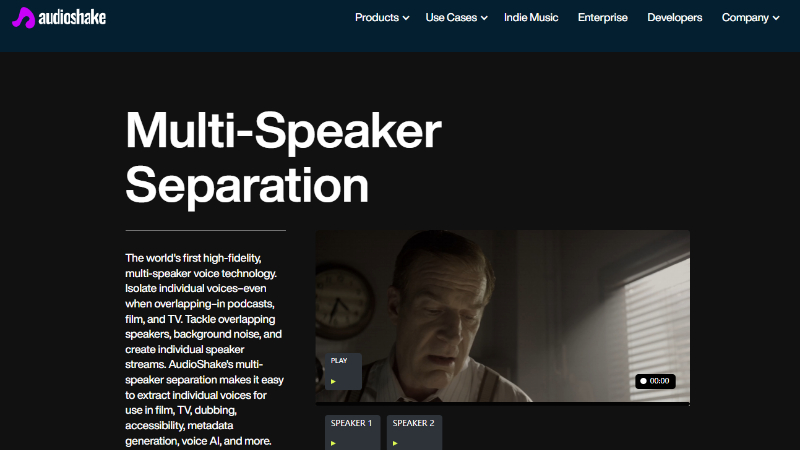
Multi-Speaker主要功能
-
精准分离不同说话人:能够将音频中各个说话人的声音分别提取出来,形成独立的音频轨道,方便后续的编辑和处理。
-
提升音频清晰度:去除音频中的背景噪音和其他干扰,让对话更加清晰,提高整体音频质量。
-
支持高质量音频处理:该模型能够处理高采样率的音频数据,确保分离后的音频质量达到专业标准,适用于广播、影视等高要求场景。
-
长时间音频处理能力:即使面对长达数小时的录音,也能保持稳定的分离效果,不会出现性能下降。
-
优化转录与字幕制作:通过分离重叠语音,显著提高语音转文字的准确性,为字幕制作提供更清晰的音频素材。
Multi-Speaker技术原理
-
深度学习技术:基于深度学习算法,通过大量的音频数据训练模型,使其能够识别和区分不同说话人的语音特征。
-
说话人特征分析:通过分析语音的声学特征(如音色、音调、语速等),模型能够准确识别出不同说话人的声音,并将其分离到独立的轨道。
-
高采样率支持:该模型能够处理高采样率的音频数据,确保分离后的音频在音质上不会损失细节,满足高质量音频处理的需求。
-
动态场景适应:模型具备强大的动态处理能力,能够应对各种复杂的音频场景,例如多人对话、背景噪音干扰等,确保在不同场景下都能保持稳定的分离效果。
Multi-Speaker应用场景
-
影视后期制作:在电影或电视剧的后期处理中,该模型能将不同角色的对话分别提取出来,方便对每条轨道单独调整音量、添加特效或进行其他优化处理,提升整体音频质量。
-
播客编辑:对于多嘉宾的播客节目,它能够清晰分离出每个嘉宾的声音,同时去除背景杂音,让播客内容更加清晰易懂,减少编辑工作量。
-
字幕生成:在多人对话的音频转录场景中,该模型可以有效分离说话人,减少转录错误,提高字幕的准确性和可读性。
-
无障碍辅助:为残障人士提供帮助,例如通过语音克隆技术,让他们用自己的声音进行交流,或者为无障碍服务提供更清晰的语音素材。
-
自媒体与短视频创作:在用户生成内容(UGC)中,创作者可以利用该模型分离音频中的不同说话人,方便对音频进行单独编辑,提升内容质量。
-
现场活动与直播:在多人参与的直播访谈、体育赛事解说等场景中,该模型能够确保每个说话人的声音都能被清晰区分,提升观众的收听体验。
Multi-Speaker项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号