OmniSQL:字节联合人大等开源的Text-to-SQL模型
OmniSQL简介
OmniSQL是由中国人民大学、字节跳动公司以及相关科研机构联合开发的开源Text-to-SQL模型。该模型基于一个创新的、可扩展的数据合成框架,能够自动生成大规模、高质量且多样化的Text-to-SQL数据集SynSQL-2.5M。OmniSQL利用这一数据集进行训练,提供三种不同参数规模(7B、14B和32B)的模型版本。在多个标准和领域特定的基准测试中,OmniSQL均展现出卓越的性能,超越了包括GPT-4o和DeepSeek-V3在内的领先模型,成为目前开源Text-to-SQL领域的新标杆。其开发团队通过开源代码、数据集和模型,为推动Text-to-SQL技术的发展和应用提供了有力支持。
OmniSQL主要功能
-
自然语言到SQL的高效转换:
-
OmniSQL能够将自然语言问题准确地转换为可执行的SQL查询语句,帮助非技术用户轻松与数据库进行交互。
-
支持多种复杂查询,包括多表连接、子查询、聚合函数等,满足不同场景下的数据查询需求。
-
-
强大的泛化能力:
-
OmniSQL在多个标准和领域特定的基准测试中表现出色,能够适应不同领域的数据库和查询需求,具有良好的泛化能力。
-
通过大规模合成数据的训练,OmniSQL能够处理未见过的数据库和复杂问题,适应多样化的应用场景。
-
-
提供详细的推理过程:
-
OmniSQL生成的每个SQL查询都附带详细的链式思考(CoT)解决方案,展示了从自然语言问题到SQL查询的逐步推理过程。
-
这不仅增强了模型的可解释性,还为开发者和研究人员提供了深入理解模型决策过程的依据。
-
-
支持多种语言风格:
-
OmniSQL能够处理多种自然语言风格的问题,包括正式、口语、命令式、疑问式、描述性、简洁、模糊、隐喻和对话式等。
-
这使得模型能够更好地理解和处理真实世界中用户提出的多样化问题。
-
OmniSQL技术原理
-
数据合成框架:
-
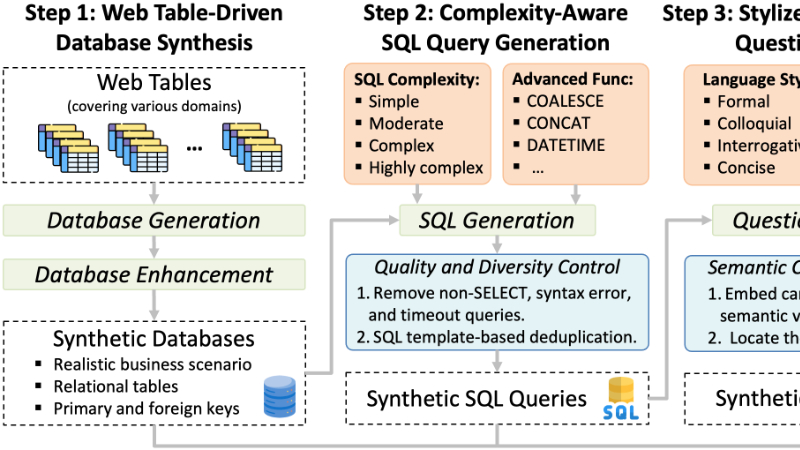
自动化和可扩展性:通过一个自动化的、可扩展的数据合成框架,OmniSQL能够自动生成大规模、高质量和多样化的Text-to-SQL数据集。
-
Web表格驱动的数据库合成:利用Web表格生成与真实业务场景相关的数据库,包括多个关系表及其结构信息。
-
复杂度感知的SQL查询生成:根据数据库信息生成不同复杂度级别的SQL查询,确保生成的查询覆盖从简单到高度复杂的各种场景。
-
风格化的自然语言问题合成:将SQL查询转换为具有不同语言风格的自然语言问题,增强模型对多样化表达的适应能力。
-
链式思考(CoT)解决方案合成:为每个合成的Text-to-SQL数据生成详细的CoT解决方案,增强数据的可解释性和训练效果。
-
-
模型训练与优化:
-
OmniSQL基于大规模合成数据集SynSQL-2.5M进行训练,通过监督学习的方式优化模型参数。
-
使用条件下一个令牌预测损失函数进行训练,确保模型能够准确生成SQL查询和详细的推理过程。
-
提供三种不同参数规模(7B、14B和32B)的模型版本,满足不同应用场景下的性能和资源需求。
-
-
推理与优化:
-
在推理阶段,OmniSQL支持贪婪解码和采样策略,通过多数投票机制选择最佳SQL查询,提高模型的准确性和鲁棒性。
-
通过详细的CoT解决方案,OmniSQL能够更好地理解和处理复杂的自然语言问题,生成准确的SQL查询。
-
OmniSQL应用场景
-
企业数据分析:帮助企业用户将自然语言问题转换为SQL查询,快速从企业数据库中获取所需数据,支持决策制定。
-
智能客服系统:作为智能客服的一部分,OmniSQL可以解析用户问题并直接从数据库中提取答案,提升客服效率和用户体验。
-
医疗数据查询:在医疗领域,OmniSQL能够帮助医生和研究人员快速查询电子健康记录(EHR)中的数据,支持临床决策和研究。
-
教育与培训:在教育领域,OmniSQL可以作为教学工具,帮助学生更好地理解和使用SQL语言,提升数据库操作技能。
-
金融数据分析:金融机构可以利用OmniSQL快速查询和分析交易数据、客户信息等,支持风险评估和市场分析。
-
科学研究:科研人员可以使用OmniSQL查询科研数据库中的数据,支持复杂的数据分析和研究工作,例如天文学、物理学等领域的数据挖掘。
OmniSQL项目入口
- Github代码库:https://github.com/RUCKBReasoning/OmniSQL
- arXiv技术论文:https://arxiv.org/pdf/2503.02240
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号