Amodal3R:南洋理工大学等推出的3D生成模型
Amodal3R简介
Amodal3R是由南洋理工大学S-Lab、牛津大学视觉几何组和新加坡科技学院联合开发的新型3D生成模型。该模型专注于从部分遮挡的2D图像中重建完整的3D物体,通过引入遮挡感知的注意力机制和遮挡感知层,Amodal3R能够直接在3D空间中完成物体的重建、补全和遮挡推理。它在多个数据集上的表现显著优于现有的两阶段方法(先进行2D模态补全再进行3D重建),并为遮挡感知的3D重建确立了新的基准。Amodal3R不仅在合成数据集上表现出色,还在真实世界的单目图像和3D场景数据集上展现了良好的泛化能力,为复杂遮挡环境下的3D资产重建提供了一种高效且高质量的解决方案。
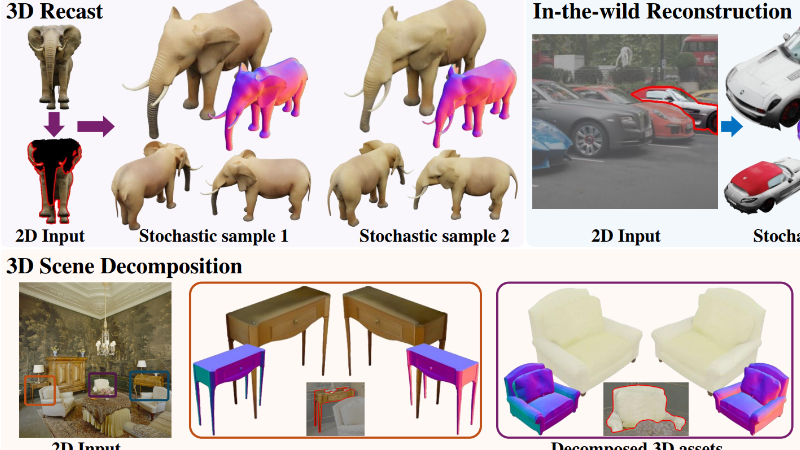
Amodal3R主要功能
-
从遮挡的2D图像重建完整的3D物体:Amodal3R能够处理部分可见的2D图像,生成完整的3D形状和外观,即使在物体被遮挡的情况下也能重建出合理的几何结构和逼真的纹理。
-
多视图一致性:支持从多个遮挡的视图输入,生成一致的3D重建结果。通过优先使用可见性较高的图像,确保多视图输入的重建质量优于单视图输入。
-
泛化能力:在多种数据集(包括合成数据集、真实世界图像和3D场景数据集)上表现出色,能够适应不同场景和物体类别的重建需求。
-
多样化结果生成:通过多次随机采样,可以从同一遮挡输入生成多种合理且语义一致的3D资产,为用户提供了更多选择。
Amodal3R技术原理
-
遮挡感知注意力机制(Mask-weighted Cross-Attention):
-
引入遮挡感知的注意力机制,使模型能够专注于物体的可见部分,同时利用遮挡信息来推断被遮挡区域。
-
通过计算每个图像块的可见性分数,对注意力权重进行加权,确保模型在重建过程中更关注可见部分。
-
-
遮挡感知层(Occlusion-aware Layer):
-
在注意力机制的基础上,增加一个专门处理遮挡信息的层,帮助模型区分可见、被遮挡和背景区域。
-
通过编码遮挡掩码,模型能够更好地理解遮挡模式,从而更准确地完成被遮挡部分的重建。
-
-
基于稀疏3D潜在空间的扩散模型(TRELLIS):
-
Amodal3R基于TRELLIS模型,该模型在稀疏3D潜在空间中进行去噪,能够生成高质量的3D几何结构和纹理。
-
通过扩展TRELLIS模型,Amodal3R能够处理遮挡物体,生成完整的3D资产。
-
-
模拟遮挡数据的生成:
-
为了训练模型,开发团队通过随机生成2D遮挡模式和3D一致的遮挡模式来模拟遮挡数据。
-
这种数据生成方式确保了模型在训练过程中能够学习到各种遮挡模式,从而提高其泛化能力。
-
-
单阶段重建流程:Amodal3R采用单阶段重建流程,直接在3D空间中完成物体的重建、补全和遮挡推理,避免了传统两阶段方法(先进行2D模态补全再进行3D重建)中的不一致性问题。
Amodal3R应用场景
-
虚拟现实(VR)和增强现实(AR):在VR和AR应用中,Amodal3R可以用于生成完整的3D模型,即使输入图像中物体部分被遮挡。这有助于增强虚拟场景的真实感和沉浸感,例如在虚拟家居布置或虚拟博物馆中。
-
3D建模和动画制作:对于3D艺术家和动画师,Amodal3R可以快速生成高质量的3D模型,减少手动建模的时间和工作量。特别是在处理复杂场景或部分遮挡的物体时,能够提供更高效的解决方案。
-
自动驾驶和机器人视觉:在自动驾驶和机器人导航中,Amodal3R可以帮助系统更好地理解复杂环境中的3D结构,即使部分物体被遮挡。这对于路径规划、障碍物检测和环境建模具有重要意义。
-
文物保护和修复:在文物保护领域,Amodal3R可以用于重建受损或部分缺失的文物的3D模型,帮助研究人员更好地研究和修复这些珍贵的文化遗产。
-
游戏开发:游戏开发者可以利用Amodal3R生成逼真的3D游戏资产,即使在资源有限的情况下,也能快速生成高质量的3D模型,提升游戏的视觉效果和用户体验。
-
医学影像分析:在医学影像领域,Amodal3R可以帮助医生和研究人员从部分遮挡的医学图像中重建完整的3D结构,例如在CT或MRI扫描中,有助于更准确地诊断和治疗疾病。
Amodal3R项目入口
- 项目官网:https://sm0kywu.github.io/Amodal3R
- HuggingFace模型:https://huggingface.co/Sm0kyWu/Amodal3R
- arXiv技术论文:https://arxiv.org/pdf/2503.13439
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号