SWEET-RL:Meta等推出的多轮强化学习框架
SWEET-RL简介
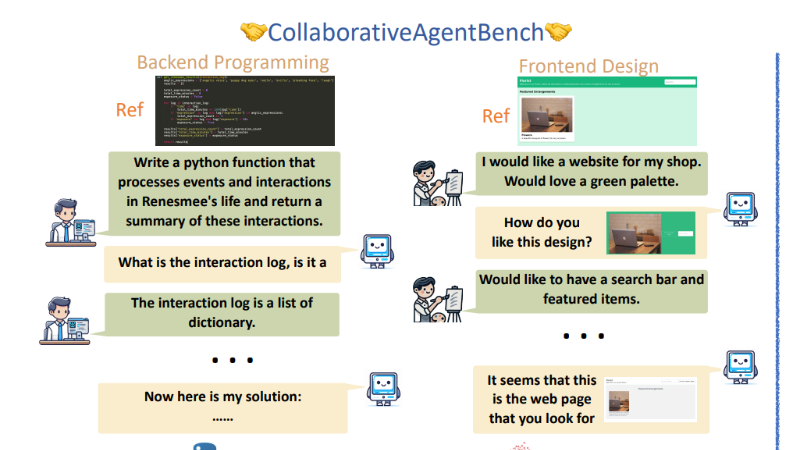
SWEET-RL是由Meta的FAIR团队和加州大学伯克利分校的研究人员共同推出的多轮强化学习框架,专门用于优化大型语言模型(LLM)代理在多轮交互任务中的表现。该算法通过引入训练时的额外信息(如最终结果和参考解决方案)来优化信用分配,从而更有效地训练策略模型。SWEET-RL的核心在于其独特的步骤级奖励机制,它利用Bradley-Terry目标函数直接训练一个优势函数,而不是传统的价值函数,从而更好地利用LLM的推理和泛化能力。实验表明,SWEET-RL在后端编程和前端设计任务中显著优于其他多轮强化学习算法,使Llama-3.1-8B模型的性能与更先进的模型相当,甚至在某些情况下超越了专有的GPT-4O模型。
SWEET-RL主要功能
-
优化多轮交互任务:SWEET-RL专门针对需要多轮交互的复杂任务进行优化,例如后端编程和前端设计。它能够帮助LLM代理在与人类合作者的多轮交互中逐步收集信息,最终生成符合人类期望的最终产品(如代码或网页)。
-
提高任务成功率和性能:通过有效的信用分配机制,SWEET-RL显著提高了LLM代理在多轮任务中的成功率和最终产品的质量。实验表明,它在后端编程任务中的成功率比其他多轮RL算法高出6%,在前端设计任务中的胜率高出5.4%。
-
利用训练时的额外信息:SWEET-RL在训练过程中利用额外的训练时信息(如最终结果和参考解决方案),从而更好地指导代理的行为,并提高其在复杂任务中的推理和泛化能力。
-
支持多种LLM架构:该算法不仅适用于特定的LLM模型,还能在不同的LLM架构上实现显著的性能提升,包括Llama-3.1-8B和Llama-3.1-70B等模型。
SWEET-RL技术原理
-
步骤级奖励机制:SWEET-RL通过引入步骤级奖励机制,为每一步的行动提供即时反馈。这种机制使得代理能够在多轮交互中逐步优化其行为,而不是仅仅依赖于最终结果的奖励。
-
训练时信息的利用:在训练过程中,SWEET-RL利用额外的训练时信息(如最终结果和参考解决方案)来优化信用分配。这些信息为代理提供了更丰富的上下文,帮助其更好地理解每一步行动的重要性。
-
Bradley-Terry目标函数:SWEET-RL使用Bradley-Terry目标函数直接训练一个优势函数,而不是传统的价值函数。这种方法避免了在复杂任务中训练准确价值函数的困难,并且更好地利用了预训练LLM的推理和泛化能力。
-
不对称的演员-评论家结构:SWEET-RL采用了不对称的演员-评论家结构,其中评论家(critic)能够访问训练时的额外信息,而演员(actor)只能访问交互历史。这种结构使得评论家能够更准确地评估每一步行动的价值,从而为演员提供更有效的指导。
-
参数化优势函数:SWEET-RL通过参数化优势函数,使用平均对数概率来评估每一步行动的效果。这种方法不仅简化了训练过程,还提高了模型的稳定性和泛化能力。
SWEET-RL应用场景
-
后端编程:与人类开发者合作编写代码,逐步澄清需求细节,生成符合要求的Python函数。
-
前端设计:与设计师合作设计网页,通过多轮反馈优化HTML代码,最终生成符合期望的网页布局和视觉效果。
-
软件开发:在软件开发过程中,与开发团队合作,逐步完善软件的功能模块,确保最终产品满足用户需求。
-
内容创作:与内容创作者合作撰写文章、报告或创意文案,通过多轮讨论优化内容质量。
-
教育辅导:在教育场景中,与学生进行多轮互动,逐步解答问题,帮助学生更好地理解和掌握知识。
-
客户服务:在客户服务中,与客户进行多轮沟通,逐步解决问题,提供个性化的解决方案,提升客户满意度。
SWEET-RL项目入口
- GitHub代码库:https://github.com/facebookresearch/sweet_rl
- HuggingFace模型:https://huggingface.co/datasets/facebook/collaborative_agent_bench
- arXiv技术论文:https://arxiv.org/pdf/2503.15478
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号