Lumina-mGPT 2.0:一款开源的自回归图像模型
Lumina-mGPT 2.0 简介
Lumina-mGPT 2.0 是一款独立的自回归图像生成模型。它从零开始训练,能够统一多种图像生成任务,包括文本到图像生成、图像对生成、主体驱动生成、多轮图像编辑、可控生成和密集预测等。该模型基于解码器架构,具有强大的图像生成能力。它还提供了快速启动指南,包括安装依赖、下载权重以及推理加速策略。此外,Lumina-mGPT 2.0 计划开源文本到图像和图像对生成的推理代码及检查点,并发布了技术报告。其 7B 参数版本支持 768px 分辨率,适用于多种生成任务,是图像生成领域的一个重要进展。
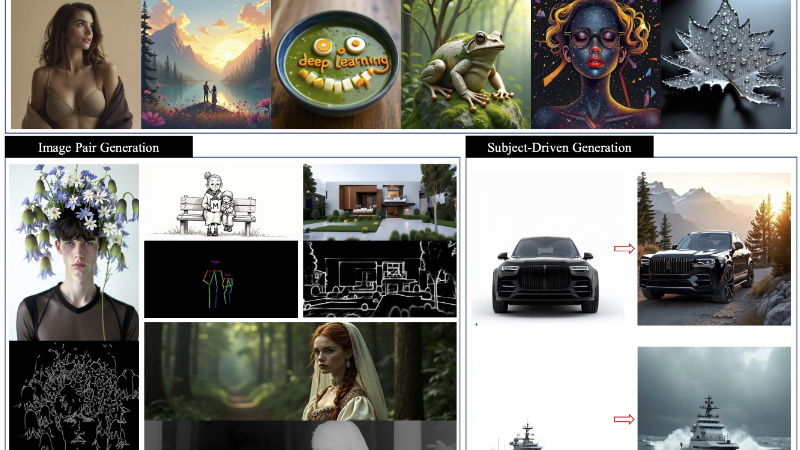
Lumina-mGPT 2.0 主要功能
-
文本到图像生成:根据输入的文本描述,生成与之对应的高质量图像。
-
图像对生成:生成与给定图像相关或匹配的另一幅图像,可用于图像扩展或对比生成。
-
主体驱动生成:以特定主体或对象为核心,生成围绕该主体的图像,突出主体特征。
-
多轮图像编辑:支持多轮交互式的图像编辑,用户可以根据前一次生成的结果进行调整和优化,逐步得到更满意的图像。
-
可控生成:用户可以通过特定的参数或指令,控制生成图像的风格、细节等特征,实现定制化生成。
-
密集预测:对图像中的像素或区域进行密集的预测和生成,可用于高分辨率图像生成或图像细节增强。
Lumina-mGPT 2.0 技术原理
-
自回归生成:采用自回归模型架构,逐像素或逐块地生成图像内容,通过学习图像数据的概率分布,逐步构建出完整的图像。
-
解码器架构:作为独立的解码器模型,专注于图像生成任务,能够高效地将输入信息(如文本描述)转化为图像输出。
-
多模态融合:将文本信息与图像信息进行融合,使模型能够理解和利用文本描述来指导图像生成,实现文本到图像的跨模态生成。
-
MoVQGAN:使用 MoVQGAN(一种改进的 VQGAN)作为图像编码器和解码器,对图像进行高效的编码和解码,提升生成质量和效率。
-
Speculative Jacobi Decoding:提供一种加速推理的策略,通过并行计算和预测,减少生成时间,同时保持生成质量。
-
模型量化:对模型进行量化处理,降低模型的计算复杂度和内存占用,进一步提升推理速度和效率,使其更适合实际应用。
Lumina-mGPT 2.0 应用场景
-
创意设计:设计师可以输入创意概念,快速生成初步设计草图或视觉效果,激发更多灵感,提升设计效率。
-
广告制作:根据广告文案生成对应的视觉素材,为广告创意提供直观的图像支持,节省广告制作成本。
-
游戏开发:用于生成游戏中的角色、场景、道具等图像资源,加速游戏美术资产的创作,丰富游戏内容。
-
影视制作:辅助生成影视概念图、场景设计图等,为影视制作提供视觉参考,帮助导演和美术团队更好地规划拍摄。
-
教育领域:教师可利用其生成与教学内容相关的图像,如历史场景、科学现象示意图等,增强教学的趣味性和直观性。
-
虚拟现实(VR)与增强现实(AR):生成虚拟场景中的元素或增强现实中的虚拟图像,提升用户体验,丰富虚拟环境。
Lumina-mGPT 2.0 项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号