Vidi:字节推出的专注于视频理解和编辑的多模态模型
Vidi项目简介
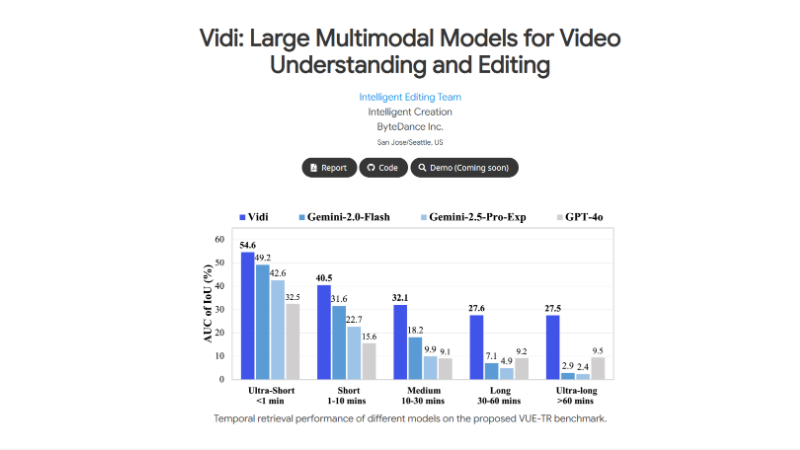
Vidi是由字节跳动公司智能创作团队开发的大型多模态模型,专注于视频理解和编辑(VUE)。它通过处理视觉、音频和文本等多种模态输入,实现对长视频的精准时间检索,能够根据自然语言查询快速定位视频中的相关片段。Vidi采用创新的分解注意力机制,显著降低了计算复杂度,使其能够高效处理长达数小时的视频内容。开发团队通过多阶段训练策略,包括多模态对齐和应用后训练,确保模型在真实场景中的优异表现。Vidi在时间检索任务上的表现显著优于其他领先的多模态模型,为视频创作和编辑提供了强大的技术支持。
Vidi主要功能
-
时间检索(Temporal Retrieval):
-
根据自然语言查询,从长视频中快速定位与查询相关的时间范围。这对于视频编辑中的片段筛选和内容查找非常关键。
-
支持多种查询格式(关键词、短语、句子)和多种模态(视觉、音频、视觉+音频),能够适应不同的用户需求和场景。
-
-
多模态视频理解:
-
同时处理视觉、音频和文本输入,提供更全面和准确的视频内容理解。
-
能够处理长达数小时的视频,支持高精度的时间定位(秒级精度)。
-
-
高效处理长视频:
-
通过分解注意力机制(Decomposed Attention),Vidi能够高效处理超长视频,突破了传统模型在视频长度上的限制。
-
适用于大规模视频内容的智能编辑和检索,显著提高视频创作的效率。
-
Vidi技术原理
-
分解注意力机制(Decomposed Attention):
-
将标准Transformer模型中的自注意力分解为视觉到视觉(V2V)、文本到文本(T2T)和文本到视觉(T2V)的注意力。
-
通过这种分解,计算复杂度从O(N²)降低到O(N),显著提高了模型的效率,使其能够处理长达数小时的视频。
-
-
多模态对齐(Multimodal Alignment):
-
适配器训练:训练视觉和音频适配器,使其能够将视觉和音频数据与相应的文本描述和时间戳对齐。
-
合成数据训练:通过合成视频和音频数据进行大规模训练,帮助模型学习多模态到时间的定位。
-
真实视频训练:在大量真实视频上进行训练,缩小合成数据和真实世界内容之间的领域差距。
-
-
应用后训练(Application Post-Training):
-
通过链式思考(CoT)提示的大型语言模型(LLM)生成用户风格的查询,并通过后处理和过滤步骤提高生成查询和时间范围的质量。
-
生成的查询和时间范围经过人工标注和验证,确保标注的准确性和一致性。
-
-
高效训练和推理:
-
采用1帧/秒的视觉采样率和16,000 Hz的音频采样率,确保模型能够以秒级精度定位和理解内容。
-
在单个80G GPU上进行推理,能够高效处理超过2小时的视频,适用于实际部署。
-
Vidi应用场景
-
视频编辑:快速定位长视频中的特定片段,帮助用户高效完成视频剪辑任务,节省时间和精力。
-
内容创作:根据用户输入的文本描述,快速找到与之匹配的视频片段,辅助创作者生成创意内容。
-
视频检索:在海量视频库中,通过自然语言查询快速找到相关视频片段,提高检索效率。
-
广告制作:快速找到适合广告创意的视频片段,提升广告制作的效率和精准度。
-
教育视频制作:帮助教育工作者快速找到与教学内容相关的视频片段,用于制作教学视频。
-
影视后期制作:在影视后期剪辑中,快速定位关键镜头和场景,提高剪辑效率和质量。
Vidi项目入口
项目地址:https://bytedance.github.io/vidi-website/
Github地址:https://github.com/bytedance/vidi
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号