ReasonIR-8B:Meta AI研究团队开发的新型检索器
ReasonIR-8B项目简介
ReasonIR-8B是由 Meta AI研究团队开发的一种新型检索器。它是首个专门针对推理密集型任务训练的检索器,通过结合公共数据和合成数据进行训练,能够有效处理复杂的推理任务。ReasonIR-8B在多个推理密集型信息检索和检索增强型生成(RAG)任务中取得了显著的性能提升,同时在测试时计算效率高,优于现有的检索器和LLM重排器。开发团队还开源了代码、数据和模型,以促进未来的研究和应用。
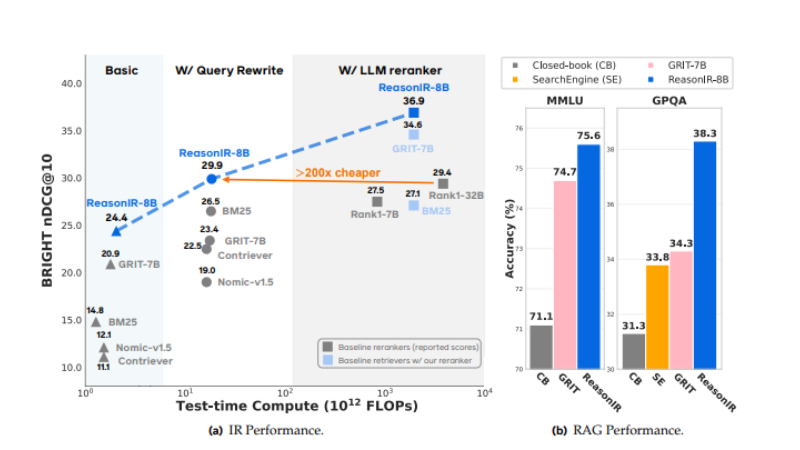
ReasonIR-8B主要功能
-
推理密集型检索:
-
专门设计用于处理需要推理的复杂查询,能够检索出有助于解决问题的广泛文档集合。
-
在推理密集型信息检索任务中表现出色,显著提升了检索质量。
-
-
检索增强型生成(RAG):
-
在RAG任务中,能够为语言模型提供更准确和相关的背景信息,从而提高生成内容的质量。
-
在MMLU和GPQA等基准测试中,显著提升了性能。
-
-
测试时计算效率:
-
在测试时,能够有效地利用计算资源,相比其他复杂的LLM重排器,计算成本大幅降低。
-
通过优化的检索策略和简单的重排方法,实现了高效的推理和生成。
-
-
合成数据生成:
-
通过ReasonIR-SYNTHESIZER生成多样化的合成数据,包括长查询、推理密集型查询和硬负样本。
-
这些合成数据帮助模型更好地学习和适应复杂的推理任务。
-
ReasonIR-8B技术原理
-
合成数据生成:
-
Varied-Length(VL)数据:生成长度多样的查询及其对应的合成文档,扩展检索器的有效上下文长度。
-
Hard Query(HQ)数据:基于高质量文档生成推理密集型查询,并为每个查询生成看似相关但实际无用的硬负样本。
-
Easy Query(EQ)数据:生成简单的查询作为对比,评估推理密集型查询的效果。
-
-
模型训练:
-
使用LLaMA3.1-8B作为基础模型,通过对比学习进行训练。
-
训练数据包括公共数据集和合成数据,以提高模型在复杂推理任务中的表现。
-
-
检索器优化:
-
采用双编码器架构,独立编码查询和文档,通过余弦相似度进行匹配。
-
通过多轮生成方法优化硬负样本的生成,提高对比学习的效果。
-
-
重排器方法:
-
提出ReasonIR-Rerank方法,通过插值检索器分数和LLM生成的分数来打破评分平局,进一步提升检索性能。
-
该方法简单且高效,能够在不增加过多计算成本的情况下显著提高检索质量。
-
-
测试时策略:
-
支持查询重写技术,通过生成更详细的查询来提高检索质量。
-
可与LLM重排器结合使用,进一步提升检索性能,同时保持较低的计算成本。
-
ReasonIR-8B应用场景
-
学术研究:帮助研究人员快速检索与复杂问题相关的学术文献和背景知识,提高研究效率。
-
教育辅导:为学生和教师提供推理问题的解答思路和相关知识点,辅助学习和教学。
-
法律咨询:检索与特定案例相关的法律条文、判例和解释,辅助法律专业人士进行案例分析。
-
医疗诊断:结合医学知识库,为医生提供与症状、诊断和治疗相关的推理性信息。
-
金融分析:检索与金融市场动态、经济理论和数据分析相关的推理性内容,辅助投资决策。
-
编程辅助:为开发者提供与代码问题、算法设计和编程技巧相关的推理性解决方案。
ReasonIR-8B项目入口
- Github仓库:https://github.com/facebookresearch/ReasonIR
- HuggingFace模型库:https://huggingface.co/reasonir/ReasonIR-8B
- arXiv技术论文:https://arxiv.org/pdf/2504.20595
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号