T2I-R1:香港中文大学等推出的文本到图像生成模型
T2I-R1项目简介
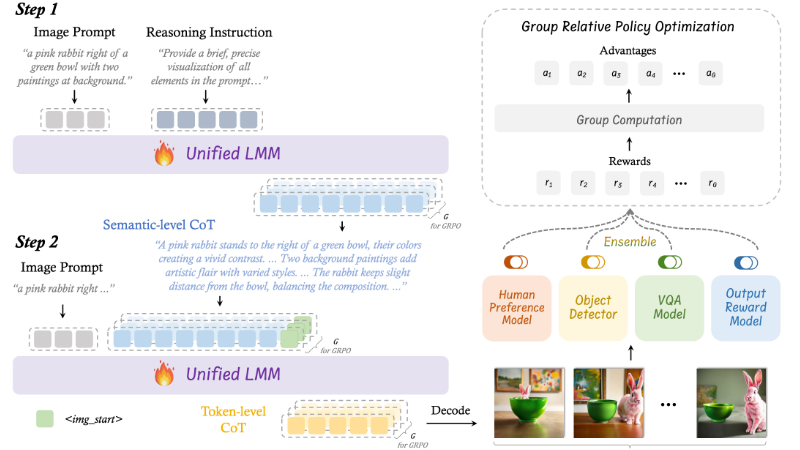
T2I-R1是由中国香港中文大学(深圳)多媒体实验室(MMLab)和上海人工智能实验室联合开发的一种新型推理增强型文本到图像生成模型。该模型通过引入双层链式推理(CoT)过程——语义级CoT和标记级CoT,显著提升了文本到图像生成的质量和准确性。开发团队提出了BiCoT-GRPO框架,利用强化学习同时优化这两种推理能力,使模型能够更好地理解复杂提示并生成高质量图像。T2I-R1在多个基准测试中表现出色,超越了现有的最先进模型,展现了其在处理复杂场景和用户意图方面的强大能力。
T2I-R1主要功能
-
高质量文本到图像生成:
-
能够根据输入的文本提示生成高质量、高分辨率的图像。
-
生成的图像能够准确反映文本描述的内容,包括对象的外观、位置和相互关系。
-
-
复杂场景理解与生成:
-
能够处理复杂的文本提示,包括包含多个对象、复杂背景和特定视觉效果的场景。
-
通过语义级推理,模型能够推断文本提示背后的真正意图,并生成符合用户期望的图像。
-
-
增强的视觉对齐能力:
-
生成的图像在视觉上与文本提示高度对齐,确保图像内容与文本描述一致。
-
能够生成具有特定属性(如颜色、形状、纹理)的对象,并正确处理对象之间的空间关系。
-
-
处理不常见或模糊场景的能力:
-
对于模糊或不常见的文本提示,模型能够通过推理生成合理的图像,避免生成不相关或混乱的结果。
-
-
支持多样化图像生成:
-
能够从同一文本提示生成多样化的图像,避免生成结果的单一性。
-
T2I-R1技术原理
-
双层链式推理(CoT):
-
语义级CoT:在图像生成之前进行的文本推理,用于设计图像的全局结构,包括对象的外观、位置和相互关系。它帮助模型推断文本提示背后的真正意图,为图像生成提供清晰的规划。
-
标记级CoT:在图像生成过程中,以块为单位逐步生成图像,关注局部像素细节和相邻块之间的视觉一致性。这一过程类似于艺术家逐步填充画布,确保生成的图像在视觉上连贯。
-
-
BiCoT-GRPO框架:
-
通过强化学习(RL)同时优化语义级和标记级CoT,使模型在生成过程中能够更好地协调全局规划和局部细节处理。
-
使用组相对策略优化(GRPO)方法,通过生成多个图像并计算组相对奖励,指导模型进行自我探索和优化。
-
-
集成奖励模型:
-
使用多种视觉专家模型(如人类偏好模型、目标检测器、视觉问答模型等)作为奖励模型,从多个维度评估生成图像的质量。
-
这些奖励模型不仅评估图像的美学质量,还检查对象的存在、属性和空间关系,确保生成的图像与文本提示高度对齐。
-
-
基于统一多模态模型(ULM)的开发:
-
T2I-R1基于能够同时处理视觉理解和生成任务的ULM开发,避免了使用单独的生成模型,降低了计算成本和复杂性。
-
通过在ULM中整合语义级和标记级CoT,模型能够更好地利用其理解能力来指导图像生成。
-
-
强化学习优化:
-
利用强化学习中的奖励机制,指导模型在生成过程中进行自我优化,逐步提升生成质量和推理能力。
-
通过多次迭代和奖励反馈,模型能够学习到更优的生成策略,生成更符合用户期望的图像。
-
T2I-R1应用场景
-
创意设计与艺术创作:艺术家和设计师可以利用T2I-R1根据创意描述快速生成设计草图或艺术作品,激发灵感并探索多种视觉风格。
-
广告与营销:广告公司可以根据广告文案生成吸引人的视觉素材,为品牌宣传和广告制作提供多样化的创意图像。
-
游戏开发:开发者可以基于游戏剧情或角色描述生成游戏场景和角色概念图,加速游戏设计和美术资源的开发流程。
-
教育与学习:教师可以利用该模型根据教学内容生成直观的图像,帮助学生更好地理解和记忆复杂的概念,例如历史场景、科学现象等。
-
虚拟现实与增强现实:在VR/AR应用中,根据用户输入的场景描述快速生成虚拟环境或增强现实元素,提升用户体验的沉浸感。
-
影视制作:影视团队可以根据剧本描述生成故事板或视觉效果预览,辅助导演和美术指导进行前期创作和场景规划。
T2I-R1项目入口
- GitHub仓库:https://github.com/CaraJ7/T2I-R1
- arXiv技术论文:https://arxiv.org/pdf/2505.00703
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号