MagicTryOn:浙大联合vivo等推出的视频虚拟试衣框架
MagicTryOn项目简介
MagicTryOn是由浙江大学计算机科学与技术学院、vivo移动通信有限公司以及BoardWare Information System Limited的联合开发团队提出的一种创新的视频虚拟试衣框架。该框架基于大规模视频扩散Transformer架构,通过粗到细的服装保留策略和掩码感知损失函数,显著提升了服装细节的保留能力和视频的时空一致性。开发团队通过引入语义引导和特征引导的交叉注意力模块,进一步增强了服装细节的生成效果。MagicTryOn在多个公开数据集上的表现优于现有的最先进方法,展现出强大的性能和泛化能力,为视频虚拟试衣领域带来了新的突破,也为在线购物体验的提升提供了新的技术支撑。
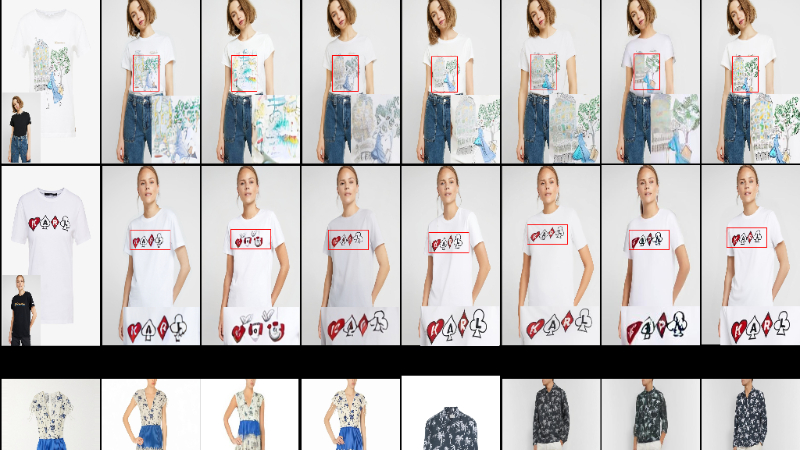
MagicTryOn主要功能
-
视频虚拟试衣:能够根据输入的人体视频和目标服装图像,生成自然逼真的试衣视频,捕捉服装在人体运动中的动态变化。
-
服装细节保留:通过粗到细的服装保留策略,精确地保留服装的纹理、图案、颜色等细节,即使在复杂的人体运动场景下也能保持服装细节的一致性。
-
时空一致性建模:确保生成视频在时间维度上的连贯性和空间维度上的稳定性,避免服装闪烁或抖动,提升视觉效果的自然性。
-
语义和结构指导:利用语义信息和服装结构特征(如轮廓线)指导生成过程,增强服装与人体的融合效果,提升整体视觉质量。
-
泛化能力:能够适应不同风格的服装和多样的人体姿态,具有良好的泛化性能,适用于多种真实场景。
MagicTryOn技术原理
-
扩散Transformer架构:基于大规模视频扩散Transformer(DiT),利用其强大的表达能力和条件信息注入能力,提升对复杂细节的建模效果。
-
粗到细的服装保留策略:
-
粗策略:在输入阶段注入服装标记(garment tokens),并通过扩展旋转位置编码(RoPE)的网格大小,使服装标记与输入标记共享一致的位置编码,为生成过程提供初步的服装结构信息。
-
细策略:在去噪阶段引入语义引导交叉注意力(SGCA)和特征引导交叉注意力(FGCA),分别利用文本标记和CLIP图像标记提供全局语义指导,以及利用服装标记和轮廓线标记提供局部细节指导,增强服装细节的生成精度。
-
-
掩码感知损失函数:通过引入基于服装掩码的损失函数,引导模型在优化过程中重点关注服装区域,提升服装细节的保真度和生成结果的整体一致性。
-
统一的时空建模:利用DiT架构中的全自注意力机制,同时对空间结构和时间动态进行建模,捕捉帧间和帧内的依赖关系,实现更精细的时空一致性建模。
-
多模态融合:通过结合文本描述、CLIP语义特征和服装轮廓线等多种信息,为生成过程提供丰富的多模态指导,提升生成结果的准确性和逼真度。
MagicTryOn应用场景
-
在线购物平台:为消费者提供虚拟试衣服务,帮助用户在购买前直观地看到服装穿在自己身上的效果,减少因尺码或款式不合适导致的退货。
-
时尚设计与展示:设计师可以利用该技术快速展示服装设计在不同模特和姿态下的效果,加速设计迭代和客户沟通。
-
虚拟服装试穿体验店:在实体店铺中提供虚拟试衣镜,顾客无需实际更换服装即可尝试多种款式,提升购物体验。
-
社交媒体与时尚博主:博主可以通过生成的试衣视频展示服装效果,吸引更多粉丝关注,同时为品牌推广提供更生动的内容。
-
服装租赁平台:帮助用户在租赁前预览服装效果,确保租赁的服装符合预期,提升用户满意度。
-
影视与广告制作:快速生成角色试穿不同服装的镜头,节省服装试穿和拍摄的时间成本,同时便于后期调整服装效果。
MagicTryOn项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号