StoryDiffusion项目介绍
StoryDiffusion是一个由字节跳动和南开大学合作推出的AI工具,专注于长范围图像和视频生成。该工具利用一致性自注意力机制来实现图像和视频内容的连续性和一致性,无论是创建漫画、卡通角色,还是生成长视频,都能保持图像风格的一致性,为用户提供高质量的视觉内容。

StoryDiffusion主要功能
❶生成连贯的图像序列:StoryDiffusion能够根据输入的文本描述或初始图像,生成一系列具有连贯性和一致性的图像序列。这些图像在角色、场景、风格等方面都保持高度统一,非常适合用于创作漫画、故事板或场景描述。
❷图像到视频的转换:除了生成静态的图像序列外,StoryDiffusion还能够将图像序列转换为流畅的视频。它通过分析图像之间的变化和运动,生成具有动态效果的视频,为创作者提供更多样化的内容表达形式。
❸角色和场景的一致性保持:StoryDiffusion特别注重角色和场景的一致性。在生成图像或视频时,它能够确保角色造型、服装、表情以及场景布局、光线等细节在不同帧之间保持一致,从而创造出连贯且引人入胜的故事情节。
❹智能优化和推荐:StoryDiffusion具备智能优化和推荐功能。它能够根据用户的历史使用数据和反馈,不断优化生成的图像和视频的质量。同时,它还可以根据用户的兴趣和偏好,推荐相关的内容模板和素材,帮助用户更高效地完成内容创作。
❺支持多种内容生成:StoryDiffusion不仅适用于漫画创作,还可以应用于广告、电影、动画等多个领域的内容生成。它可以根据用户的需求和风格要求,生成符合特定场景和情感的图像和视频内容。
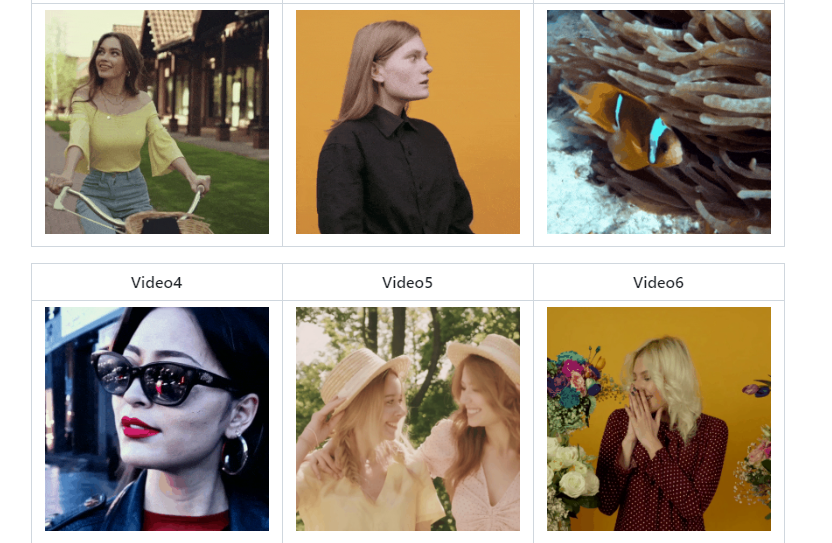
StoryDiffusion应用场景
❶漫画生成:StoryDiffusion特别擅长于生成连贯的漫画序列。通过一致性自注意力机制,它能够确保角色风格和服装的一致性,从而创作出连贯且吸引人的漫画故事。
❷广告与电影制作:在广告或电影制作中,StoryDiffusion可以生成连续的场景和角色动作,帮助创作者快速构建故事框架,并生成符合故事情节和情感的图像和视频素材。
❸教育材料设计:教育工作者可以利用StoryDiffusion设计引人入胜的教育视频或互动故事,以增强学习者的参与度和兴趣。例如,它可以用于制作动画教程、科学实验演示等教学材料。
❹娱乐内容创作:在娱乐领域,StoryDiffusion可以生成各种风格的图像和视频内容,如动画短片、游戏场景、虚拟现实体验等,为创作者提供丰富的素材和灵感。
StoryDiffusion技术原理
❶一致性自注意力机制(Consistent Self-Attention):这是StoryDiffusion的核心技术之一。自注意力机制是一种特殊的注意力机制,它允许模型在处理序列数据(如图像序列或文本序列)时,根据序列中不同位置的信息进行自适应的加权。一致性自注意力机制在此基础上进行了优化,以确保生成的图像序列在角色、场景和风格等方面保持一致性。
❷生成对抗网络(GANs):GANs是一种强大的生成模型,由生成器和判别器两个部分组成。生成器负责生成新的数据样本,而判别器则负责判断生成的数据样本是否真实。在StoryDiffusion中,GANs被用于训练生成器以生成高质量的图像序列,同时训练判别器以区分生成的图像序列和真实的图像序列。
❸图像到视频转换:StoryDiffusion不仅可以生成静态的图像序列,还可以将图像序列转换为视频。这主要依赖于一种称为运动预测器(Motion Predictor)的模块,它负责预测不同帧之间的运动信息,从而生成流畅的动态视频。
❹零次学习(Zero-shot Learning):StoryDiffusion还采用了一种零次学习的方法,这使得模型能够在无需额外训练的情况下,根据新的文本提示或条件图像生成相应的图像序列或视频。这种方法大大提高了模型的灵活性和可扩展性。
StoryDiffusion项目入口
- GitHub源码库:https://github.com/HVision-NKU/StoryDiffusion
- arXiv研究论文:https://arxiv.org/abs/2405.01434
相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号