AtomoVideo项目介绍
AtomoVideo是一款由阿里巴巴研究团队开发的先进图像到视频(I2V)生成框架。它采用前沿的AI技术,能够将静态图像快速、高效地转化为高质量、高保真度的动态视频。AtomoVideo注重细节与真实感,生成的视频在风格、内容和细节上都与原始图像保持高度一致。同时,它还支持文本引导的视频生成,为用户提供了更多样化的创作可能。阿里巴巴研究团队在开发过程中,充分考虑了技术的普适性和实用性,使得AtomoVideo能够满足不同场景下的需求,为影视制作、广告设计、游戏开发等领域带来革新性的用户体验和内容生产力提升。
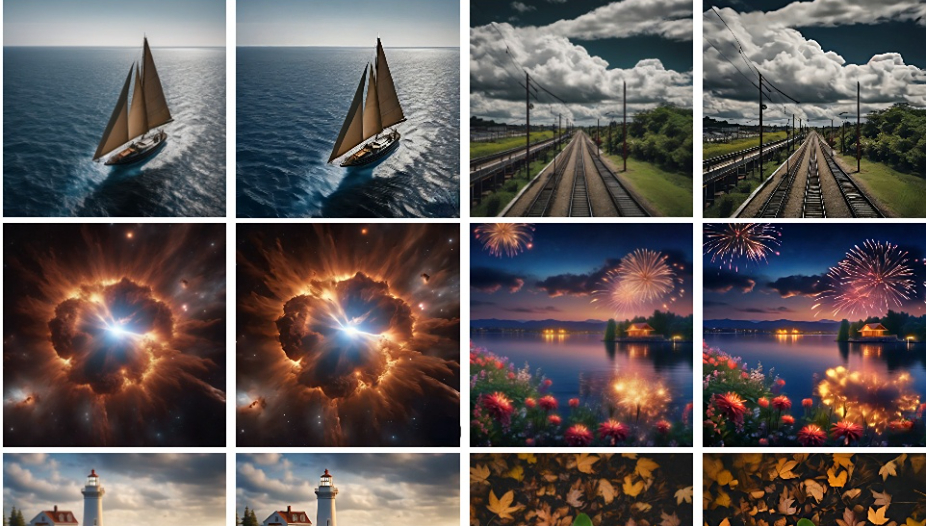
AtomoVideo主要功能
❶高保真图像到视频生成:AtomoVideo 能够将静态图像转换成视频,同时保持与原始图像的高度一致性。
❷运动强度和一致性:该框架不仅注重生成视频的细节保真度,还强调生成视频的运动强度和时间上的一致性。
❸可控性:通过设计适配器训练,AtomoVideo 支持与可控模块的结合,使用户能够对生成的视频进行一定程度的控制和定制。
❹长视频序列生成:通过迭代生成的方式,AtomoVideo 能够生成较长的视频序列,超越了传统方法在视频长度上的限制。
❺文本到视频生成:结合先进的文本到图像模型,AtomoVideo 还能够实现文本描述直接生成视频的能力。
AtomoVideo应用场景
❶电影和视频制作:可以用来生成特效场景或者预览最终的视频效果,帮助导演和视觉效果团队在实际拍摄前进行规划。
❷游戏开发:在游戏设计中,AtomoVideo 可以用来生成游戏内动画或者预告片,提高游戏的视觉吸引力。
❸广告行业:用于创造引人注目的广告视频,通过将静态图像转换成动态视频来吸引潜在客户。
❹社交媒体内容创作:内容创作者可以使用 AtomoVideo 生成动态内容,增加帖子的互动性和吸引力。
❺艺术和动画:艺术家和动画师可以利用 AtomoVideo 探索新的创作方式,生成独特的艺术作品。
❻教育和培训:在教育领域,可以生成模拟场景视频,用于培训或教学目的,如模拟手术过程或历史事件重现。
❼新闻和纪录片:可以用于生成历史事件的重现视频,或者为新闻报道增添视觉元素。
AtomoVideo技术原理
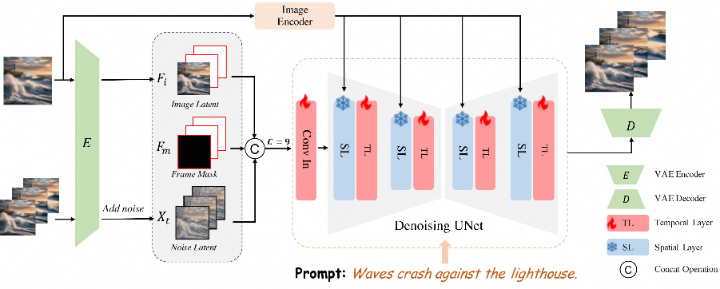
❶预训练的文本到图像(T2I)模型:AtomoVideo 使用了一个预训练的 T2I 模型作为基础,该模型能够将文本描述转换成高质量的图像。
❷多粒度图像注入:为了提高生成视频与给定图像的保真度,AtomoVideo 在生成过程中采用了多粒度的图像注入技术。这意味着它会在不同的层次上注入图像信息,包括低级的视觉信息和高级的语义信息。
❸1D 时间卷积和时间注意力模块:在每个空间卷积和注意力层之后,AtomoVideo 新增了 1D 时间卷积层和时间注意力模块。这些新增的层只在训练过程中进行训练,而预训练的 T2I 模型参数保持固定。
❹输入通道的修改:AtomoVideo 将输入通道修改为 9 个通道,并添加了图像条件潜在因子和二进制掩码。这样的设计使得模型能够编码低级信息,从而增强视频与给定图像的保真度。
❺交叉注意力机制:通过交叉注意力机制,AtomoVideo 能够在生成过程中注入高级图像语义,实现更多的语义图像可控性。
❻迭代生成:AtomoVideo 能够通过迭代生成的方式,预测视频序列中接下来的帧,从而实现长视频序列的生成。
❼训练策略:在训练过程中,AtomoVideo 使用了零终端信噪比(zero terminal SNR)和 v-prediction 策略,这些策略有助于在没有噪声先验的情况下提高生成稳定性。
❽个性化和可控性:AtomoVideo 的设计允许它与现有的个性化模型和可控模块结合,通过适配器训练的方式,使得模型可以灵活地适应不同的个性化需求。
AtomoVideo项目入口
- 官方项目主页:https://atomo-video.github.io/
- arXiv研究论文:https://arxiv.org/abs/2403.01800
相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号