EMO项目介绍
EMO(Emote Portrait Alive)是由阿里巴巴集团智能计算研究所开发的先进框架,它利用音频驱动的视频生成技术,通过扩散模型直接从音频信号合成具有丰富表情和自然头部动作的人物肖像视频。该框架能够保持视频中角色身份的一致性,并根据输入音频的时长生成相应长度的视频,显著提升了生成视频的表达性和逼真度,为虚拟助手、电影制作、游戏开发等多个领域提供了强大的技术支持。(目前在通义APP上可直接使用)

EMO主要功能
❶生成表达性视频:EMO 能够生成具有丰富面部表情和多样化头部姿势的视频。
❷与音频同步:生成的视频与输入的音频紧密同步,包括语音的语调和强度变化。
❸身份保持:确保视频中角色的面部特征与输入的参考图像保持一致。
❹长时间视频生成:可以根据输入音频的长度生成任意时长的视频。
❺高表现力和逼真度:在表达性和逼真度方面,EMO 显著优于现有的最先进方法。
❻多样化的风格生成:尽管在现实风格的视频上训练,但 EMO 也能够处理不同风格的人物图像,如动漫或3D风格,并保持一致的唇形同步。
❼处理复杂音频:EMO 能够处理具有明显音调特征的音频,如歌唱,并在生成的视频中产生更丰富和动态的面部表情。
EMO应用场景
❶虚拟助手和客服:使用 EMO 生成的视频可以创建虚拟助手或客服代表,它们能够以逼真的面部表情和头部动作与用户进行交流。
❷电影和视频制作:在电影后期制作或视频内容创作中,EMO 可以用来生成演员的面部动画,尤其是在需要特定表情或情感表达的场景中。
❸游戏开发:在游戏角色设计中,EMO 可以用于生成具有丰富表情和流畅动作的角色动画,提升游戏的互动性和沉浸感。
❹教育和培训:通过生成教师或讲师的虚拟形象,EMO 可以用于创建教育内容,特别是在语言学习和情感表达教学中。
❺新闻和广播:EMO 可以用于生成新闻主播的虚拟形象,为新闻播报增添更加自然和吸引人的视觉元素。
❻社交媒体:用户可以利用 EMO 生成具有个性化表情和动作的虚拟形象,用于社交媒体平台上的内容创作和分享。
EMO技术原理
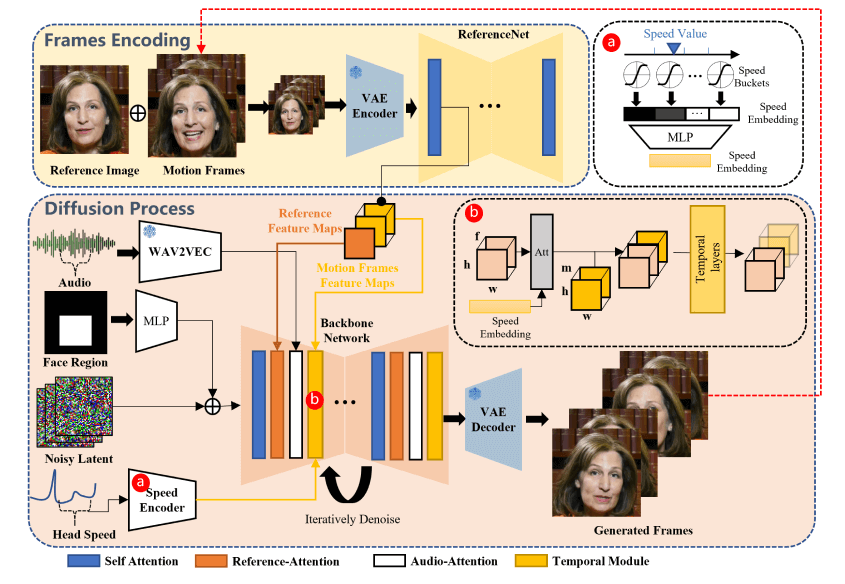
❶音频驱动的视频生成:EMO 框架使用音频信号(如说话或唱歌的声音)来驱动视频内容的生成。
❷扩散模型:它利用扩散模型直接从音频合成视频,无需依赖于3D模型或面部标记的中间步骤。
❸帧编码:通过一个称为 ReferenceNet 的模块,该框架能够从参考图像中提取特征,并在视频生成过程中保持角色身份的一致性。
❹稳定性控制:通过速度控制器和面部区域控制器,增强了视频生成过程中的稳定性,这些控制器作为超参数,提供微妙的控制信号,同时不牺牲生成视频的多样性和表达性。
❺训练策略:训练过程分为三个阶段,包括图像预训练、视频训练和速度层的整合。
❻数据集:使用了一个庞大且多样化的音频-视频数据集,包括演讲、电影和电视片段以及歌唱表演,涵盖中文和英文等语言。
❼网络架构:包括 Backbone Network、Audio Layers、ReferenceNet、Temporal Modules、Face Locator 和 Speed Layers,这些组件协同工作以生成连贯且逼真的视频。
EMO项目入口
相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号