VideoPoet项目介绍
VideoPoet是谷歌团队开发的一款先进的AI视频生成模型。它凭借预训练的tokenizer和自回归语言模型,实现了文本到视频、视频风格化等多种功能,并能在视频、图像、音频和文本间进行跨模态学习。谷歌开发团队凭借其深厚的技术积累和创新能力,成功打造了这一强大的视频生成工具,为用户带来了全新的视觉体验。

VideoPoet主要功能
❶文本到视频生成:VideoPoet 能够根据用户提供的文本描述生成对应的视频内容。这种能力允许用户通过简单的文字输入来创建具有特定情节、场景和动作的视频。
❷视频风格迁移:模型可以将一种视频的风格迁移到另一种视频上,例如将卡通风格应用到真实世界的视频中,或者将某个艺术家的风格应用到其他视频素材上。
❸视频修复和扩展:VideoPoet 还能用于修复损坏的视频片段,或者根据已有视频的内容来扩展其长度,增加新的场景或动作。
❹视频到音频的生成:除了视频生成外,该模型还能从视频中提取信息来生成音频,例如根据视频中的动作和场景来生成背景音乐或声效。
❺多模态学习:VideoPoet 能够在视频、图像、音频和文本之间进行跨模态学习,这使得它能够处理更复杂和多样化的任务。
VideoPoet应用场景
❶娱乐和社交媒体:用户可以利用 VideoPoet 生成个性化的视频内容,用于社交媒体平台,比如创造带有特定风格的舞蹈视频或动画短片。
❷广告和营销:公司可以使用该模型来设计吸引人的广告视频,快速生成与品牌风格一致的宣传材料。
❸教育和培训:在教育领域,VideoPoet 可以用来创建教育视频,比如模拟实验过程或历史事件,增强学习体验。
❹电影和视频制作:视频制作人员可以利用该模型进行前期制作,快速生成视频草图,帮助预览最终产品或辅助编辑决策。
VideoPoet技术原理
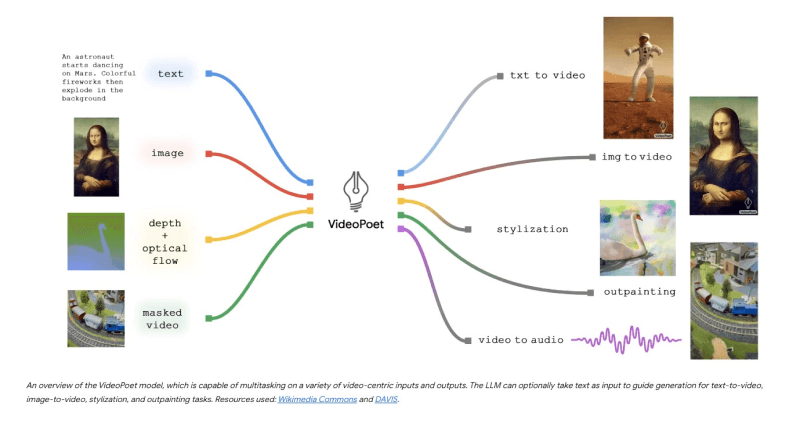
❶多模态输入处理:模型能够接收并解析包括图像、视频、文本和音频在内的多种类型的输入数据。
❷大型语言模型架构:基于变换器(Transformer)架构的大型语言模型,用于学习和生成视频内容。
❸自回归生成机制:通过自回归方法逐步构建视频的每一帧,确保时间上的连贯性。
❹预训练与任务适应:模型首先在多模态数据上进行预训练,然后针对特定任务进行微调。
❺零样本学习能力:即使没有直接的训练样本,模型也能够生成或编辑视频内容。
❻超分辨率技术:通过特定的变换器模块提升生成视频的分辨率,增强视觉细节。
VideoPoet项目入口

相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号