ActAnywhere项目介绍
ActAnywhere是由斯坦福大学和Adobe Research的联合团队开发的一款先进的视频生成模型。它专注于自动化生成与前景主体动作相匹配的视频背景,利用大规模视频扩散模型的能力,实现与艺术家创意意图相协调的背景合成。该技术在电影制作、视觉特效、广告创意等领域具有广泛的应用潜力,能够显著提升内容创作的效率和灵活性。

ActAnywhere主要功能
❶自动化背景生成:ActAnywhere能够自动生成与前景主体动作相匹配的视频背景,这在电影制作和视觉效果制作中非常有用,因为它减少了传统上需要的手动编辑工作。
❷主题意识:该模型是“主题意识”的,意味着它能够理解和适应前景主体的动作和外观,以及艺术家的创意意图。
❸条件帧遵循:模型使用一个描述所需场景的图像作为条件,生成的视频背景与该条件帧保持一致。
❹大规模数据集训练:ActAnywhere在大规模的人类场景交互视频数据集上进行训练,使其能够生成与多种场景相匹配的背景。
❺泛化能力:模型不仅能够处理人类主体,还能够泛化到非人类主体,显示了强大的泛化能力。
ActAnywhere应用场景
❶电影制作:在电影拍摄过程中,可以将演员的表演合成到任何所需的背景中,这为导演提供了更大的创作自由度,并且可以减少实地拍摄的成本和风险。
❷视觉效果(VFX):在后期视频制作中,ActAnywhere可以用来生成复杂的背景,如战斗场景、灾难场景或其他难以实际拍摄的环境,从而增强视觉效果。
❸广告制作:广告中经常需要将产品放置在特定的环境或情境中,使用ActAnywhere可以在不实际搭建场景的情况下,快速生成吸引人的广告视频。
❹游戏开发:在游戏设计中,可以利用该技术为游戏角色生成多样化的虚拟背景,提升游戏的沉浸感和玩家的体验。
❺虚拟试衣:在时尚和零售行业,ActAnywhere可以用于生成模特试穿衣服的虚拟背景,帮助顾客更好地预览服装在不同环境中的效果。
ActAnywhere技术原理
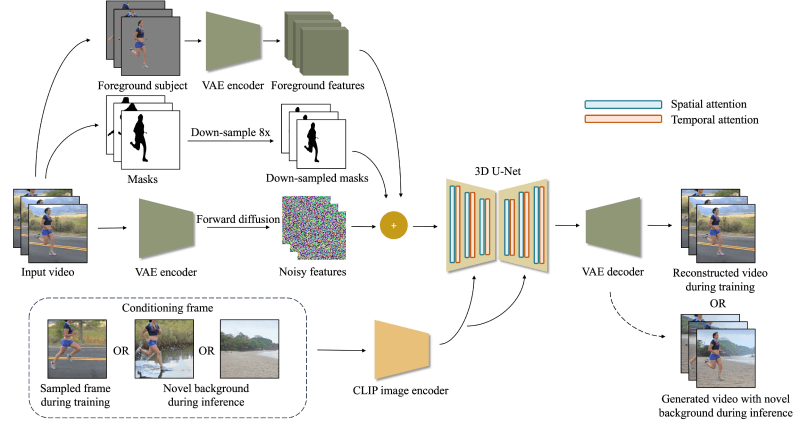
❶3D U-Net架构:ActAnywhere使用一个3D U-Net网络,这是一种用于医学图像分割的卷积神经网络的扩展,它能够处理视频数据。
❷前景分割序列:模型接受前景主体的分割序列和相应的掩码作为输入,这些分割数据定义了视频中前景的轮廓和形状。
❸条件帧:在训练时,模型使用从训练视频中随机抽取的帧作为条件,以指导去噪过程。在测试时,条件可以是带有新背景的合成帧,或者仅是背景图像。
❹大规模视频扩散模型:ActAnywhere利用大规模视频扩散模型的能力,这是一种生成模型,通过逐步添加和去除噪声来生成数据。
❺自监督训练:模型以自监督的方式进行训练,这意味着它使用的数据没有显式的标签,而是从数据本身学习模式和结构。
❻时间注意力机制:模型使用时间注意力机制来理解视频中的时间关系,从而生成与前景主体动作相一致的背景。
❼生成细节:ActAnywhere能够生成具有高度现实感的视频,包括移动或交互的对象和阴影,同时保持一致的摄像机比例和光照效果。
❽零样本学习:尽管模型主要在人类视频数据集上训练,但它能够以零样本的方式泛化到非人类主体,这意味着它可以在没有特定主体类型训练数据的情况下生成背景。
ActAnywhere项目入口
- 官方项目主页:https://actanywhere.github.io/
- arXiv研究论文:https://arxiv.org/abs/2401.10822
相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号