OpenELM简介
OpenELM是由苹果公司开发的一款开源的大型语言模型(LLM),专为提高效率和透明度而设计。它采用了逐层扩展策略,优化了transformer模型中参数的分配,使得在有限的参数预算下能够实现更高的准确性。OpenELM在公开可用的数据集上进行了预训练,并且在多个任务上展现了出色的性能,特别是在需要较少预训练数据的情况下,与其他类似规模的模型相比,准确率有显著提升。此外,OpenELM的发布包括了完整的训练和评估框架,以及在公开数据集上的预训练配置,旨在促进开放研究和社区的进一步发展。

OpenELM技术架构
❶逐层扩展策略:OpenELM采用了一种非均匀的参数分配方法,通过调整每个transformer层中的注意力头数和前馈网络的乘数,实现了在不同层中的参数数量变化。这种方法允许模型在保持参数总数大致相同的情况下,更有效地利用参数来提高性能。
❷解码器仅Transformer架构:作为一个解码器仅模型,OpenELM专注于生成文本任务,不涉及编码器-解码器架构中常见的编码部分。
❸优化的注意力机制:OpenELM使用了分组查询注意力代替传统的多头注意力,以提高效率。
❹改进的前馈网络:模型中的前馈网络被替换为SwiGLU FFN,这是一种改进的激活函数,旨在提高模型的表达能力。
❺高效的注意力计算:通过使用Flash Attention技术,OpenELM能够以更高效的方式计算缩放点积注意力。
❻RMSNorm预归一化:在模型的各个部分使用RMSNorm进行预归一化,有助于稳定训练过程。
❼旋转位置嵌入:用于编码序列中的位置信息,与传统的固定位置嵌入不同,ROPE可以更灵活地处理序列数据。
OpenELM性能表现
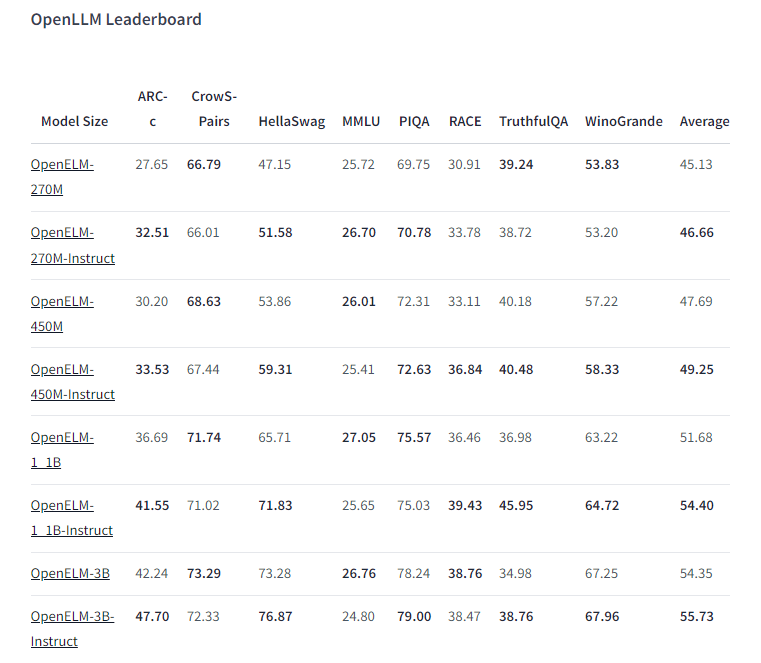
❶准确率提升:在与同类大型语言模型(LLM)的比较中,OpenELM展现出了更高的准确率。例如,在1.1亿参数的配置下,OpenELM在多个任务上比具有1.2亿参数的OLMo模型高出2.36%的准确率,同时所需的预训练数据更少。
❷参数效率:OpenELM通过层级扩展策略优化了参数的使用,使得在有限的参数预算内能够实现更高的性能,这显示了其参数效率的优势。
❸多种任务表现:OpenELM在多种自然语言处理任务上进行了评估,包括但不限于常识推理、知识理解以及关于错误信息和偏见的评测。它在这些任务上都展现出了良好的性能。
❹零样本和少样本学习:OpenELM在零样本和少样本学习设置下的性能表现也得到了评测,这表明了模型在面对未见过的任务时的适应性和灵活性。
❺预训练数据集:OpenELM使用了公开可用的数据集进行预训练,包括RefinedWeb、去重的PILE、RedPajama的一个子集和Dolma v1.6的一个子集,这些数据集的多样性有助于提升模型的泛化能力。
❻模型变体:OpenELM提供了不同大小的模型变体,从270M到3B参数不等,以适应不同的应用需求和计算资源限制。
❼推理效率:尽管OpenELM的主要焦点是模型的可复制性和准确性,但它在推理效率方面也进行了评估。在NVIDIA CUDA/Linux和Apple macOS平台上的基准测试显示了模型在实际部署时的性能。
❽优化潜力:通过对模型的全面分析,发现RMSNorm实现是性能瓶颈之一。通过优化这一部分,OpenELM有进一步提高推理效率的潜力。
OpenELM项目入口
相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号