Llama 3简介
Llama 3是Meta公司最新开源推出的大型语言模型,具有8B和70B两种参数规模,支持广泛的语言处理任务。它在超过15万亿个token的大规模数据集上进行预训练,涵盖30多种语言,显著提升了多语言能力。Llama 3采用了先进的指令微调技术,如监督微调(SFT)、拒绝采样等,确保了在对话和编码任务中的高性能。同时,它还引入了严格的安全措施,如Llama Guard 2,以识别潜在的不安全内容。此外,Meta正在开发一个超过400亿参数的高级版本,将引入多模态能力和扩展的语言支持。Llama 3的推出,不仅推动了大型语言模型技术的民主化,也为全球开发者和研究人员提供了一个更高效、更可靠、更安全的AI工具,有望在自然语言处理领域带来新的突破。

Llama 3模型规模与版本
Llama 3提供了两种规模的版本:
❶8B(80亿参数)版本:这是一个相对较小的模型,但即便如此,它仍然能够提供强大的语言处理能力。这个版本适合于需要在消费级硬件上运行模型的场景,同时保持较高的性能。
❷70B(700亿参数)版本:这个版本拥有更大的参数规模,能够处理更复杂的任务,并提供更精细的语言理解能力。它适合于需要极高精确度和深度理解的应用场景。
每个规模的模型都提供了两种类型:
❶基础预训练模型:这些模型在大规模数据集上进行了预训练,能够处理广泛的语言任务。
❷指令微调模型:这些模型专门为对话应用程序和需要遵循具体指令的场景进行了优化。
Llama 3性能表现
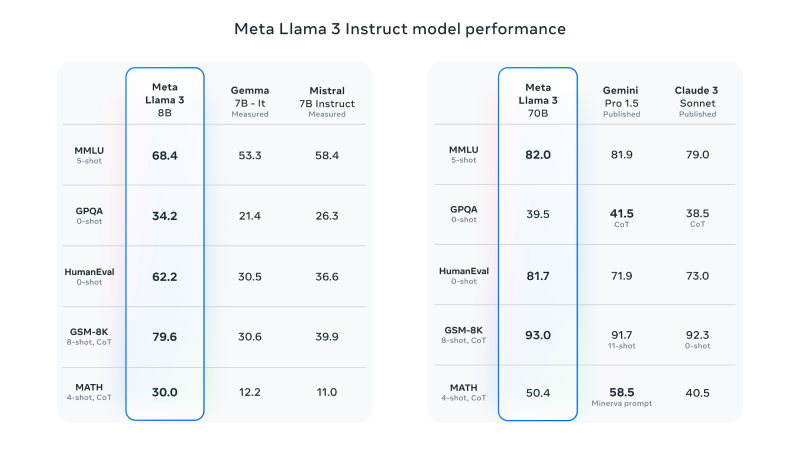
❶Llama 3在多个关键的基准测试中表现优异,性能直逼GPT-4。
❷在代码生成等任务上实现了全面领先,能够进行复杂的推理,并且可以更遵循指令。
❸在MMLU、HumanEval和GSM-8K测试中,Llama 3胜过了Gemini 1.5 Pro,显示了其在自然语言理解、代码执行和长文本处理等多个领域的强大性能。
❹特别是在编程相关的任务中,如HumanEval编程测试,Llama 3 70B版本的准确率高达81.7%,是上一代Llama 2的近3倍。
Llama 3模型架构与训练数据
❶Llama 3采用了相对标准的decoder-only Transformer架构,并在模型架构上进行了一些关键改进,如使用包含12.8万个token的词表进行更高效的编码。
❷Llama 3支持8192个token的序列长度,意味着模型可以处理更长的文本段落,并更好地理解上下文信息。
❸训练数据规模达到了15万亿个token,是Llama 2的七倍,包含四倍于Llama 2的代码数据,以及覆盖30多种语言的非英语数据,为模型的多语言能力奠定了基础。
Llama 3项目入口
相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号