Mora简介
Mora是由微软和理海大学研究人员联合开发的多智能体视频生成框架,旨在模仿并扩展OpenAI的Sora视频生成模型。它通过将视频生成任务分解为多个子任务,并为每个子任务指派专门的智能体,实现了高度灵活的视频内容创作。Mora能够处理文本到视频、图像到视频以及视频编辑等多种任务,支持生成高分辨率且时间持续12秒的视频。尽管在处理复杂物体运动场景时与Sora存在性能差距,Mora的开源特性和多样化功能使其成为一个具有潜力的多用途视频生成工具。

Mora主要功能
❶文本到视频生成:根据用户提供的文本描述自动生成相应的视频内容。
❷图像到视频生成:结合用户提供的初始图像和文本提示,生成与之相匹配的视频序列。
❸扩展生成视频:对现有的视频内容进行扩展和编辑,增加新的元素或延长视频的持续时间。
❹视频到视频编辑:根据用户的文本指令对视频进行编辑,如改变场景、调整对象属性或添加新元素。
❺连接视频:将两个或多个视频片段无缝连接起来,创造出流畅的过渡效果。
❻模拟数字世界:创建和模拟数字世界,根据文本描述创造出具有数字世界风格的视频序列。
Mora应用场景
❶广告制作:根据广告文案快速生成视频内容,节省创意和制作时间,提高效率。
❷社交媒体内容:为社交媒体平台创建吸引人的视频,增强用户互动和内容分享。
❸教育和培训:生成教学视频,帮助解释复杂概念或模拟实验过程,提高学习效果。
❹游戏开发:用于生成游戏预告片或游戏内动画,提升游戏体验和市场吸引力。
❺电影和视频编辑:辅助电影制作中的特效生成,或在视频后期制作中快速编辑和拼接视频片段。
Mora技术原理
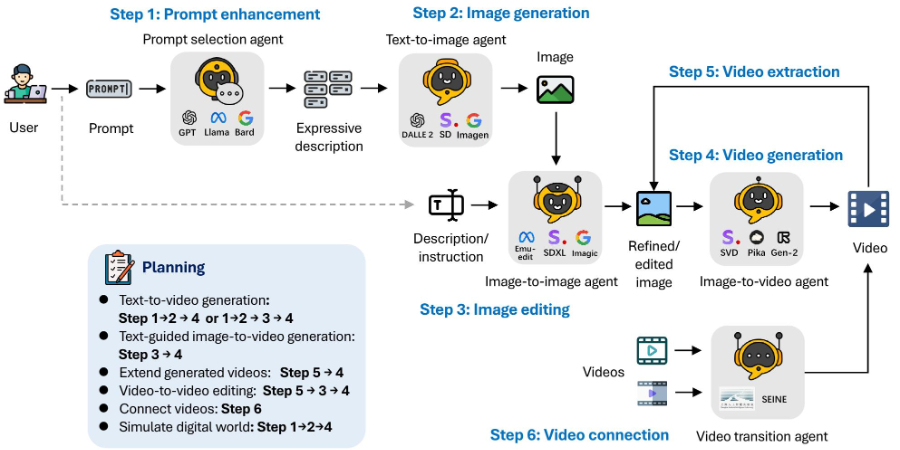
- 多智能体框架:Mora采用多智能体方法,将视频生成任务分解为多个子任务,每个子任务由一个专门的智能体完成。这种模块化方法提高了灵活性和扩展性。
- 任务分解:视频生成任务被分解为以下子任务:
- 提示选择与生成(Prompt Selection and Generation)
- 文本到图像生成(Text-to-Image Generation)
- 图像到图像生成(Image-to-Image Generation)
- 图像到视频生成(Image-to-Video Generation)
- 视频到视频编辑(Video-to-Video Editing)
- 视频连接(Video Connection)
- 智能体角色定义:Mora定义了五种基本类型的智能体,每种智能体都有特定的功能和专长:
- 提示选择与生成智能体:使用大型语言模型(如GPT-4或Llama)来优化和选择文本提示,提高生成图像的相关性和质量。
- 文本到图像生成智能体:将文本提示转换为高质量的初始图像。
- 图像到图像生成智能体:根据文本指令修改给定的源图像。
- 图像到视频生成智能体:将静态图像转换成动态视频序列。
- 视频连接智能体:基于两个输入视频创建平滑过渡的视频。
- 工作流程:Mora根据任务需求,自动组织智能体按照特定的顺序执行子任务。例如,文本到视频的生成任务可能包括以下步骤:
- 首先,提示选择与生成智能体处理文本提示。
- 接着,文本到图像生成智能体根据优化后的文本提示生成初始图像。
- 然后,图像到视频生成智能体将初始图像转换成视频序列。
- 最后,如果需要,视频连接智能体可以将多个视频片段连接成一个连贯的视频。
- 多智能体协作:智能体之间通过预定义的接口和协议进行通信和协作,确保整个视频生成过程的连贯性和一致性。
- 生成与评估:每个智能体完成其子任务后,会将结果传递给下一个智能体,直至完成整个视频生成流程。生成的视频可以根据预定义的评估标准进行质量评估。
- 迭代与优化:Mora框架允许通过迭代和优化来改进视频生成的质量。智能体可以根据反馈调整其参数,以提高生成视频的质量和与文本提示的一致性。
Mora项目入口
- Arxiv论文:https://arxiv.org/abs/2403.13248
- GitHub地址:https://github.com/lichao-sun/Mora
相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号