Open-Sora简介
Open-Sora是由Colossal-AI团队全面开源的视频生成模型,它复现了OpenAI Sora的视频生成能力,旨在促进AI视频创作的发展。该模型基于Diffusion Transformer(DiT)架构,通过图像预训练、视频预训练和微调三个阶段来生成与文本描述匹配的视频内容。Open-Sora 1.0版本公开了整个训练流程,包括数据处理、训练细节和模型权重,鼓励全球AI爱好者参与学习和创新。Colossal-AI团队承诺将持续优化Open-Sora,计划引入更多视频数据,支持多分辨率,以提升视频质量和长度,推动AI技术在电影、游戏、广告等多个领域的应用。

Open-Sora主要功能
❶文本到视频生成:用户输入文本描述,模型根据描述自动生成视频内容,实现从文本到视觉内容的转换。
❷视频内容编辑:支持对生成的视频内容进行编辑,包括视频到视频的转换,允许用户对现有视频进行修改或风格化处理。
❸多分辨率和多纵横比支持:能够处理和生成不同分辨率和纵横比的视频,适应不同的播放需求和设备。
❹训练和推理加速:通过采用高效的训练策略和技术,如加速变换器、更快的 T5 模型等,提高模型的训练和推理速度。
❺数据预处理和管理:提供自动化的数据预处理流程,帮助用户从原始视频中提取高质量的视频-文本对,以供模型训练使用。
❻模型权重和配置共享:公开模型权重和配置细节,使得其他研究者和开发者可以复现结果,或在现有基础上进行进一步的研究和开发。
Open-Sora应用场景
❶影视:在电影、电视剧或短片制作中,可以用来生成特效场景或背景视频,减少实际拍摄成本和时间。
❷游戏:在电子游戏或虚拟现实应用中,可以用于生成动态的游戏环境或过场动画,增强玩家的沉浸感。
❸广告创意:广告行业中,可以根据广告概念快速生成吸引人的视频内容,提高广告创意的制作效率。
❹社交媒体:内容创作者可以利用 它生成独特的视频内容,用于社交媒体平台,吸引观众并增加互动。
❺教培:在教育领域,Open-Sora 可以用来创建教学视频,帮助解释复杂的概念或展示历史事件的重现。
Open-Sora技术原理
❶Diffusion Transformer (DiT) 架构:采用扩散模型与变换器结合的架构来生成视频内容。
❷时间注意力层:在模型中加入时间注意力机制,以处理视频数据中的时间序列特性。
❸三阶段训练:包括大规模图像预训练、大规模视频预训练和高质量视频数据微调,逐步提升模型生成视频的能力。
❹加速技术:使用加速变换器、更快的 T5 和 VAE,以及序列并行性等技术来提高训练效率。
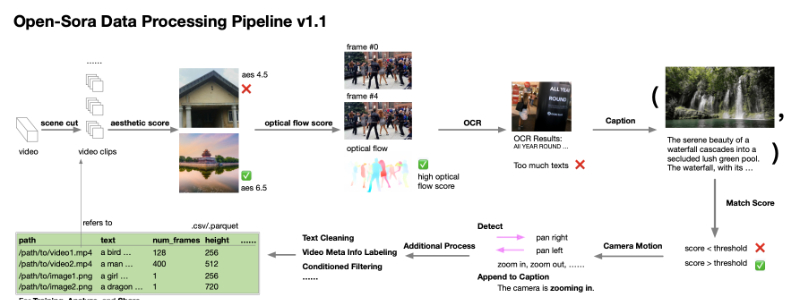
❺视频处理流程:包括场景切割、过滤(美学、光流、OCR等)、字幕生成和管理,以构建高质量的视频数据集。
❻模型权重初始化:模型权重部分初始化自 PixArt-α,这是一个开源的基于 DiT 的文本到图像模型。
❼文本编码和图像编码:使用强大的文本编码器(如 T5)和图像编码模型(如 CLIP)来增强文本和图像内容的理解与生成。
❽图像和视频条件:支持图像和视频的条件生成,使得生成的视频更加符合给定的条件或风格。
❾视频编辑支持:允许用户对生成的视频进行编辑,包括动画图像和连接视频等
Open-Sora项目入口
- 官网项目主页:https://hpcaitech.github.io/Open-Sora
- Github开源地址:https://github.com/hpcaitech/Open-Sora
相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号