Slicedit项目介绍
Slicedit是由Technion – 以色列理工学院的研究团队开发的一种创新视频编辑技术。这项技术基于预训练的文本到图像扩散模型,通过利用时空切片来增强视频编辑过程中的时间一致性。Slicedit能够处理长视频,特别是那些包含复杂非刚性运动和遮挡的视频,同时能够保留未在文本提示中指定的区域,例如仅将视频中的人替换为机器人而保持背景不变。通过广泛的实验验证,Slicedit展示了其在编辑真实世界视频方面的优势,相比现有方法,它在保持视频原有结构和运动的同时,能够更好地遵循目标文本的指导。团队的工作在机器学习领域的顶级会议发表,并通过他们的网站提供了视频结果的展示。

Slicedit主要功能
❶零样本视频编辑:无需针对特定任务进行训练,直接使用预训练模型对视频进行编辑。
❷复杂视频处理:能够处理包含复杂非刚性运动和遮挡的长视频。
❸指定区域编辑:根据文本提示,仅更改视频中指定的区域,如将人物替换为机器人。
❹背景保留:在编辑过程中保留未在文本提示中指定的区域,例如保持背景不变。
❺时间一致性:确保编辑后的视频在时间维度上保持一致性,避免闪烁或漂移现象。
❻结构和运动保持:在遵循目标文本的同时,保留原始视频的结构和运动特征。
Slicedit应用场景
❶电影和视频制作:在后期视频制作中,对特定场景或对象进行修改,如将演员替换为特效角色或改变场景背景。
❷虚拟现实和游戏开发:在虚拟现实环境或游戏中,根据用户输入或脚本自动生成或调整视频内容。
❸社交媒体内容创作:用户可以根据自己的描述,快速生成或编辑视频内容,用于社交媒体平台分享。
❹教育和培训视频:在教育领域,根据教学需求对视频资料进行定制化编辑,如突出显示教学重点或模拟实验过程。
❺新闻和纪录片编辑:在新闻报道或纪录片制作中,对采访视频或现场录像进行必要的编辑,以符合叙事需求或传达特定信息。
Slicedit技术原理
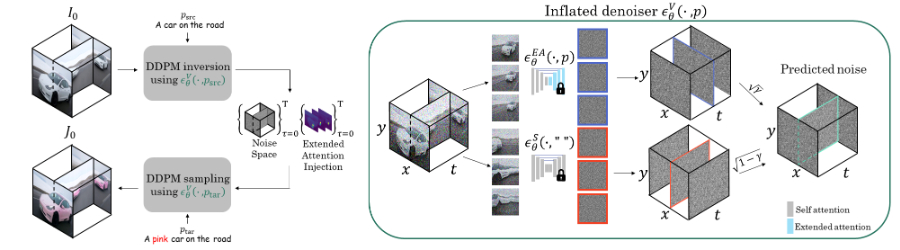
❶预训练的文本到图像扩散模型:使用现成的文本到图像的扩散模型作为基础,该模型能够根据文本描述生成相应的图像。
❷时空切片:观察到自然视频的时空切片与自然图像具有相似特征,因此可以应用同一预训练模型来处理视频的时空切片,以增强时间一致性。
❸扩展注意力机制:通过对模型中的自注意力模块进行修改,使其能够跨帧处理信息,从而捕捉帧与帧之间的动态关系。
❹多轴去噪:除了对视频帧进行去噪外,Slicedit还对视频体的时空切片进行去噪处理,这有助于在编辑时只改变指定区域,而保持其他内容不变。
❺DDPM逆向方法:使用DDPM(去噪扩散概率模型)逆向方法来提取给定视频的噪声向量序列,然后结合用户提供的文本提示重新生成视频,同时固定噪声向量并注入源视频的逆向特征。
Slicedit项目入口

相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号