V-Express项目介绍
V-Express是一种先进的肖像视频生成技术,由南京大学和腾讯AI实验室的研究人员共同开发。这项技术通过渐进式训练和条件性丢弃操作,解决了在生成控制信号中强弱信号平衡的难题。特别地,它强化了音频信号这类通常较弱的控制信号,使得生成的视频不仅面部表情和口型与音频同步,还能保持与参考图像的一致性。V-Express利用潜在扩散模型(LDM)生成视频帧,并集成了ReferenceNet、V-Kps引导器和音频投影模块来有效处理各种控制输入。通过三个阶段的渐进式训练,V-Express能够生成与音频输入同步的高质量肖像视频,为虚拟头像、数字娱乐和个性化视频内容创作等领域提供了强大的支持。此外,该研究还提出了未来工作的方向,包括多语言支持、减少计算负担和显式面部属性控制等潜在改进。
V-Express主要功能
❶高质量视频生成:能够从单幅图像生成高质量的肖像视频。
❷音频同步:生成的视频能够与输入的音频同步,包括口型和面部表情与音频信号的一致性。
❸多控制信号处理:有效整合文本、音频、参考图像、关键点和深度图等多种控制信号。
❹弱信号增强:特别强化了通常较弱的控制信号,如音频,以提高生成视频的控制精度。
❺面部身份和姿态保持:在视频生成过程中保持与参考图像的面部身份和姿态一致性。
❻渐进式训练:通过分阶段训练提高模型对控制信号的响应和生成视频的质量。
❼条件性丢弃:使用条件性丢弃技术避免模型学习到直接复制强控制信号的捷径,平衡不同信号的影响。
V-Express应用场景
❶虚拟助手和客服:生成虚拟形象,提供更加自然和亲切的客户服务体验。
❷数字娱乐:在游戏或虚拟现实中创建逼真的非玩家角色(NPC)或虚拟偶像。
❸个性化视频内容创作:允许用户通过上传图片和音频来创建个性化的视频内容,如音乐视频或个人传记视频。
❹社交媒体:用户可以利用自己的肖像和声音生成动态视频,用于社交媒体分享。
❺电影和视频制作:辅助电影制作中的特效制作,或生成特定角色的动画视频。
❻教育和培训:创建教育内容中的虚拟讲师或角色,提供互动式学习体验。
V-Express技术原理
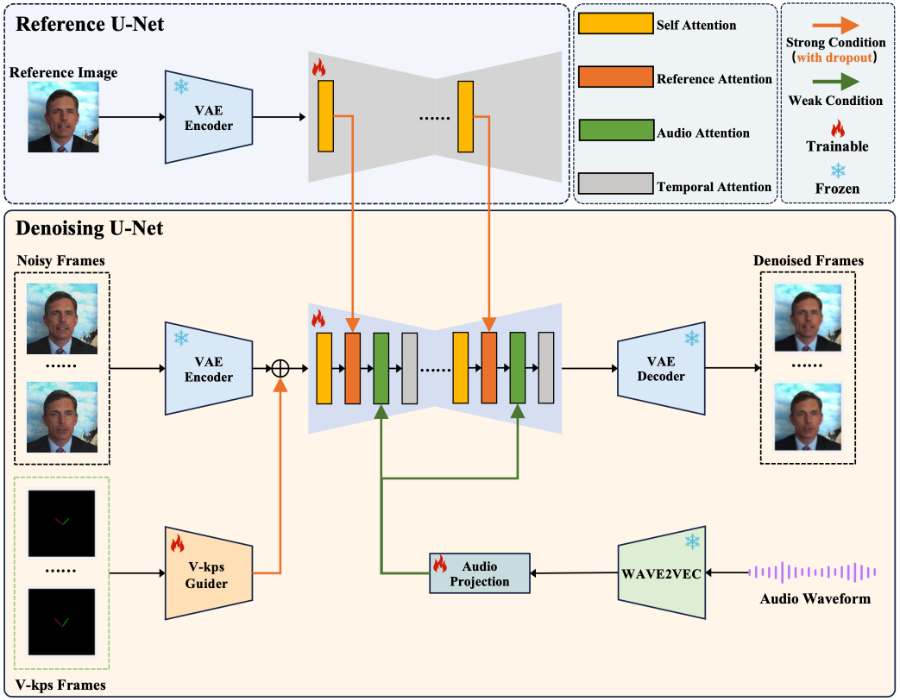
❶潜在扩散模型(Latent Diffusion Model, LDM):用于生成视频帧,通过变分自编码器(Variational Auto-Encoder, VAE)在潜在空间中执行扩散和逆扩散过程。
❷条件性丢弃(Conditional Dropout):在训练过程中,随机丢弃一些帧的参考图像和V-Kps特征,以防止模型学习到直接复制这些强控制信号的捷径,从而平衡不同控制信号的影响。
❸渐进式训练策略:训练过程分为三个阶段,分别专注于单帧生成、多帧生成和全局微调,逐步提升模型对控制信号的响应能力。
❹多模块集成:包括ReferenceNet、V-Kps Guider和Audio Projection,分别用于编码参考图像、V-Kps图像和音频,以有效处理各种控制输入。
❺运动注意力层(Motion Attention Layer):捕捉视频帧之间的时间关系,确保生成的视频帧具有平滑和连贯的过渡效果。
❻强化音频信号:通过调整注意力层的权重,增强音频信号对视频生成过程的影响,特别是对口型同步的控制。
V-Express项目入口
- GitHub源码库:https://github.com/tencent-ailab/V-Express
- arXiv研究论文:https://arxiv.org/abs/2406.02511
- Hugging Face模型:https://huggingface.co/tk93/V-Express

相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号