Seed-TTS项目简介
Seed-TTS是由字节团队开发的一款先进的文本到语音(TTS)模型系列,它能够生成与人类语音几乎无法区分的高质量语音。这些模型在语音上下文学习、说话者相似度和自然度方面表现出色,无论是客观还是主观评估均与真实人类语音相匹配。Seed-TTS通过自监督学习和强化学习方法,提供了对语音属性如情感和语调的出色控制能力。此外,Seed-TTS还引入了一种新颖的非自回归变体Seed-TTSDiT,该变体基于完全扩散模型,通过端到端处理实现语音生成,不依赖预先估计的音素持续时间。Seed-TTS的这些特性使其在虚拟助手、有声读物、视频配音等多种应用场景中具有广泛的应用潜力。

Seed-TTS主要功能
❶高质量语音生成:能够生成与人类语音极为相似的合成语音。
❷上下文学习:在零样本情况下,根据简短的参考语音片段生成具有相同音色和韵律的新语音。
❸说话者相似度:通过微调,可以提高特定说话者的语音相似度。
❹情感控制:能够根据文本内容生成具有特定情感色彩的语音。
❺语音属性控制:提供对语音属性(如情感、语速、风格等)的精细控制。
❻跨语言能力:支持多语言的语音合成,有助于跨语言交流和内容创作。
❼语音编辑:支持对生成的语音进行内容编辑和语速调整。
Seed-TTS应用场景
❶虚拟助手:为用户提供自然、流畅的语音交互体验。
❷有声读物:将电子书或文档转换为有声内容,供用户听书。
❸视频配音:为视频内容生成配音,特别是在内容创作和电影制作中。
❹客户服务:在呼叫中心或自动客服系统中提供自然的语言回复。
❺语言学习:帮助语言学习者练习发音和听力,提供标准的语音示例。
❻辅助技术:为有视觉障碍或阅读困难的人提供文本到语音的服务。
Seed-TTS技术原理
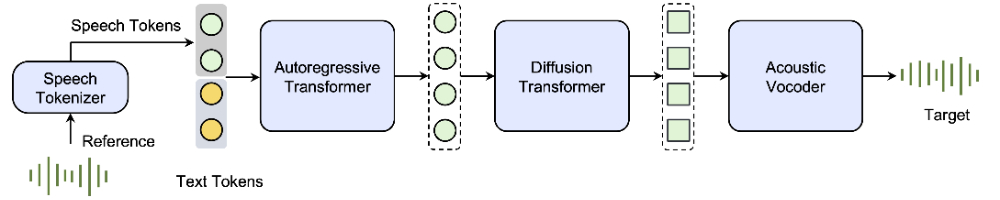
❶自回归变换器模型:基于自回归变换器(autoregressive transformer)构建,该模型能够按顺序生成语音信号。
❷语音分词器:将语音信号转换为一系列语音分词(speech tokens)。
❸语言模型:训练一个基于文本和语音分词配对的自回归语言模型,用于生成语音分词。
❹扩散变换器:用于增强生成的语音分词的声学细节,以生成连续的语音表示。
❺声码器:将扩散变换器的输出转换为高质量的语音波形。
❻自监督学习:通过自监督学习的方法,在大量数据上训练模型,以提高泛化能力和语音建模的鲁棒性。
❼强化学习:使用强化学习技术进行模型的后训练,以全面提高模型性能。
❽非自回归变体:Seed-TTSDiT作为非自回归模型,采用基于扩散的架构直接预测输出语音的潜在表示,实现端到端的语音生成。
❾语音因子分解:通过自蒸馏方法实现语音属性的分解,提高语音合成的可控性。
❿偏好偏差:利用外部奖励模型通过强化学习对特定语音属性进行优化,以满足特定偏好。
Seed-TTS项目入口
- 官方项目主页:https://bytedancespeech.github.io/seedtts_tech_report/
- GitHub源码库:目前未公布代码
- arXiv研究论文:https://arxiv.org/abs/2406.02430
相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号