StreamSpeech项目简介
StreamSpeech是由中国科学院计算技术研究所智能信息处理重点实验室(ICT/CAS)团队研发的先进同声传译模型。该系统采用多任务学习框架,实现实时语音识别、翻译和合成的一体化处理,为用户提供低延迟、高质量的语音翻译服务。通过创新的两阶段架构和连接主义时序分类(CTC)技术,StreamSpeech在多种语言对的翻译任务中展现出卓越的性能,适用于国际会议、直播、医疗咨询等多种实时通信场景。

StreamSpeech主要功能
❶实时语音识别:将输入的语音流实时转换为文本。
❷同声传译:在接收语音的同时,生成目标语言的语音翻译。
❸语音合成:将翻译后的文本转换为流畅自然的语音输出。
❹低延迟通信:优化模型以减少通信延迟,提供实时的翻译体验。
❺多语言支持:虽然文档中以特定语言对为例,但模型设计支持多语言翻译。
StreamSpeech应用场景
❶国际会议:为来自不同国家的与会者提供实时语言翻译,确保沟通无障碍。
❷多语言直播:在直播活动中,为不同语言的观众实时提供语音翻译,增强观看体验。
❸法庭和法律程序:在涉及多语言参与者的法律场合,提供实时翻译服务。
❹医疗咨询:在多语言环境中,帮助医生与患者进行有效沟通。
❺紧急服务:在紧急情况下,为不同语言的受害者或求助者提供即时翻译,确保信息准确传达。
❻旅游和客户服务:在旅游和服务业中,为不同语言背景的客户提供实时语音翻译服务。
StreamSpeech技术原理
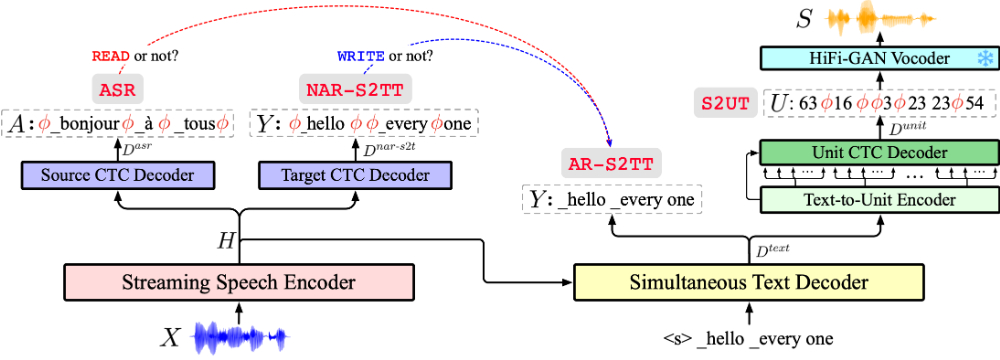
❶多任务学习:通过统一框架同时学习语音识别、翻译和合成任务,实现任务间的相互促进和优化。
❷两阶段架构:首先将源语音转换为目标文本隐藏状态,然后生成目标语音。
❸连接主义时序分类(CTC):用于学习源语音与文本之间的对齐,以及文本与单元之间的转换。
❹自回归与非自回归结构:在翻译任务中使用自回归结构以处理语言的依赖性,在语音合成中使用非自回归结构以提高效率。
❺流式编码器:特别设计的编码器处理实时语音流,适应连续输入的特性。
❻策略学习:模型学习确定最优的翻译时机,以生成连贯的目标语音输出。
❼端到端优化:所有组件在训练过程中共同优化,提高了整体性能和翻译质量。
StreamSpeech项目入口
- 官方项目主页:https://ictnlp.github.io/StreamSpeech-site/
- GitHub源码库:https://github.com/ictnlp/StreamSpeech
- arXiv研究论文:https://arxiv.org/pdf/2406.03049
- Hugging Face模型:https://huggingface.co/ICTNLP/StreamSpeech_Models/tree/main
相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号