VideoTetris项目简介
VideoTetris是由北京大学和快手科技的联合研究团队开发的一项创新技术,旨在解决传统文本到视频生成模型在处理复杂场景时的局限性。该框架通过引入时空组合扩散技术,精准地根据文本描述动态调整视频内容,实现多对象和动态变化场景的自然融合。此外,它还采用了增强的视频数据预处理和参考帧注意力机制,以提高视频生成的连贯性和动态表现力。VideoTetris在生成符合复杂文本提示的视频内容方面展现出了卓越的性能,为视频内容创作和自动媒体生成开辟了新的可能性。

VideoTetris主要功能
❶组合式视频生成:能够根据文本提示生成包含多个对象和复杂场景的视频。
❷长视频生成:支持生成具有连续变化和动态对象数量的长视频。
❸高精度语义遵循:确保视频内容与文本描述的精确对应,包括对象的位置和属性。
❹高质量视频输出:生成的视频具有高运动动态和视觉效果,类似于叙事视频。
VideoTetris应用场景
❶剧本视觉化:将电影剧本转化为视频草图,辅助导演规划拍摄。
❷广告创意:基于文案快速生成视频广告,提升创意效率。
❸社交媒体:创作者制作与热点相关视频,增加内容吸引力。
❹教育辅助:将复杂概念制作成视频,提高学习兴趣和效果。
❺游戏开发:从文本描述生成游戏动画,加速游戏设计。
❻新闻制作:快速生成新闻事件视频,增强报道生动性。
VideoTetris技术原理
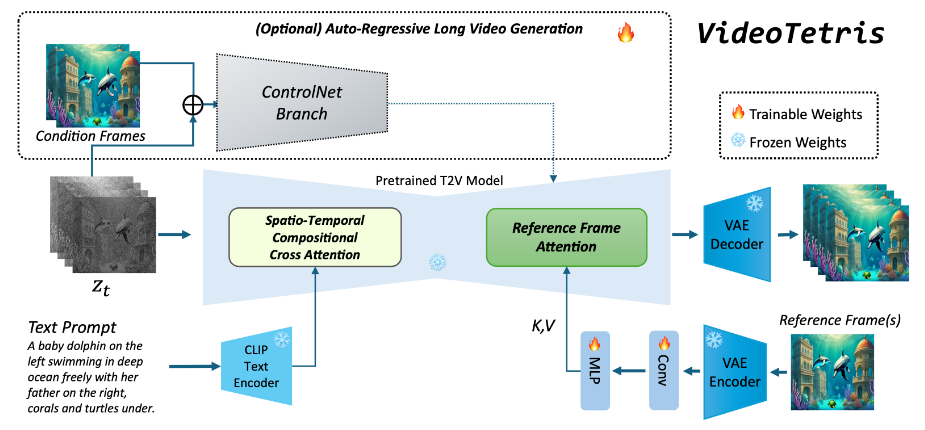
❶时空组合扩散:通过在空间和时间上操作去噪网络的注意力图,实现对复杂文本语义的精确遵循。
❷增强的视频数据预处理:通过筛选和增强训练数据,提高模型对运动动态和文本提示的理解。
❸参考帧注意力机制:通过在自回归视频生成中引入一致性正则化,保持对象在不同帧中的一致性。
❹大规模语言模型辅助的时空分解:利用LLM的理解和推理能力,自动进行文本提示的时空分解,提高视频生成的自然性和合理性。
❺训练自由方法:该方法可以直接应用于现有的文本到视频模型,无需额外训练,提高了灵活性和效率。
VideoTetris项目入口
- 官方项目主页:https://videotetris.github.io/
- GitHub源码库:https://github.com/YangLing0818/VideoTetris
- arXiv研究论文:https://arxiv.org/abs/2406.04277

相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号