Omost简介
Omost是一款由ControlNet的作者张吕敏开发的创新工具,它巧妙地将大型语言模型的编码能力转化为图像生成能力。用户只需通过简单的文字描述,Omost便能自动生成精确且富有创意的图像,支持自动写提示词和会话模式改图,为用户提供了前所未有的图像创作体验。无论是专业人士还是普通用户,都能通过Omost轻松实现创意视觉表达。
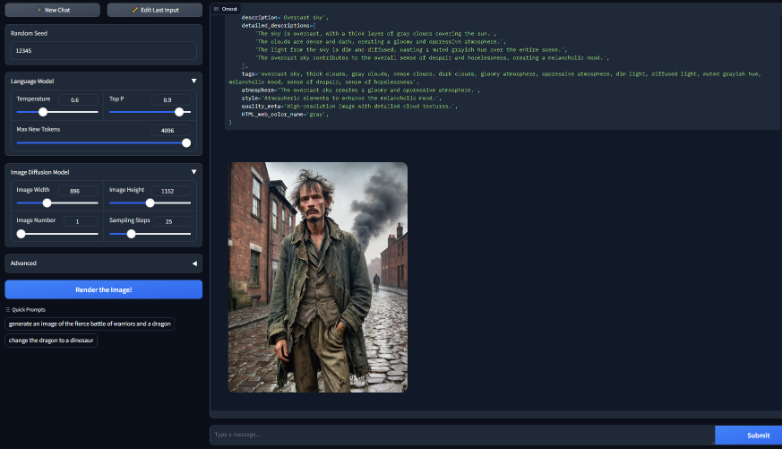
Omost功能特色
❶自动写提示词:Omost能够自动生成关键词,帮助用户解决不会写提示词的痛点。
❷会话模式改图:如果用户对第一次生成的图片效果不满意,可以通过“聊天”方式再次发布会话内容,修改上次生成的内容。
❸模型基础:项目提供三种基于Llama3和Phi3变体的预训练LLM模型,这些模型已经针对多个数据源组合进行了训练。
❹注意力操作技术:项目包含区域提示器和提示前缀树等注意力操作技术,用于改善提示理解和图像生成效果。
Omost应用场景
❶创意艺术设计:艺术家和设计师使用Omost将文字描述转化为独特的艺术作品。
❷教育资源制作:教师和教育工作者利用Omost快速生成教学素材,如科学示意图、历史场景等。
❸游戏开发:游戏开发者使用Omost创建游戏角色、场景和道具的草图或概念图。
❹市场营销与广告:营销人员借助Omost生成吸引人的广告图像和社交媒体内容。
❺虚拟现实与增强现实:在VR/AR项目中,Omost用于生成虚拟环境中的图像和场景。
❻科研与可视化:科研人员利用Omost将复杂的数据和概念转化为直观的图像,便于理解和交流。
Omost技术原理
- 大型语言模型(LLM):
- Omost利用大型语言模型(LLM)的编码能力,将文本描述转化为图像生成所需的参数或指令。
- 通过预训练的LLM模型,Omost能够编写代码来组合图像视觉内容。
- 虚拟Canvas代理:
- Omost的虚拟Canvas代理能够理解并实现对图像内容的详细描述。
- 该代理将用户输入的文本描述转化为计算机可以理解的图像生成指令。
- 图像生成器:
- 特定的图像生成器根据虚拟Canvas代理输出的指令,生成最终的图像。
- 结合大语言模型的能力,Omost能够重新解构画面,并加入更多的元素,提升画面美感度。
- 注意力操作技术:
- 项目包含区域提示器和提示前缀树等注意力操作技术,用于改善提示理解和图像生成效果。
- 这些技术帮助Omost更准确地理解用户意图,并生成更符合用户期望的图像。
项目入口
- GitHub源码库:https://github.com/lllyasviel/Omost
- Hugging Face Demo:https://huggingface.co/spaces/lllyasviel/Omost
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号