Stability AI正式开源最新文生图模型-Stable Diffusion 3 Medium
Stable Diffusion 3 Medium简介
2024年6月12日,Stability AI正式发布开源其最新文生图模型-Stable Diffusion 3 Medium。Stable Diffusion 3 Medium 包含 20 亿个参数,是 Stability AI 迄今为止最先进的文本到图像开放模型。该模型体积小巧,非常适合在消费级 PC 和笔记本电脑以及企业级 GPU 上运行。它通过技术创新提升了对复杂提示的理解力,优化了文本排版质量,具备生成更高质量图像的能力,包括细节丰富、色彩真实和灵活风格。Stability AI通过与NVIDIA和AMD的合作,进一步优化了模型性能,同时提供开放许可,鼓励专业和业余用户探索和使用。
Stable Diffusion 3 Medium要点
❶先进性:Stable Diffusion 3 Medium 是 Stability AI 迄今为止最先进的文本到图像的开放模型。
❷兼容性:该模型体积小,非常适合在消费级个人电脑和笔记本电脑以及企业级 GPU 上运行。
❸许可选项:该模型的权重在两种许可下可用:开放的非商业许可和低成本的创作者许可。对于大规模商业用途,请联系 Stability AI 了解许可详情。
❹试用和测试选项:要体验 Stable Diffusion 3 模型,用户可以使用 Stability 平台上的 API,注册 Stable Assistant 的免费三天试用,并通过 Discord 尝试 Stable Artisan。
Stable Diffusion 3 Medium优势
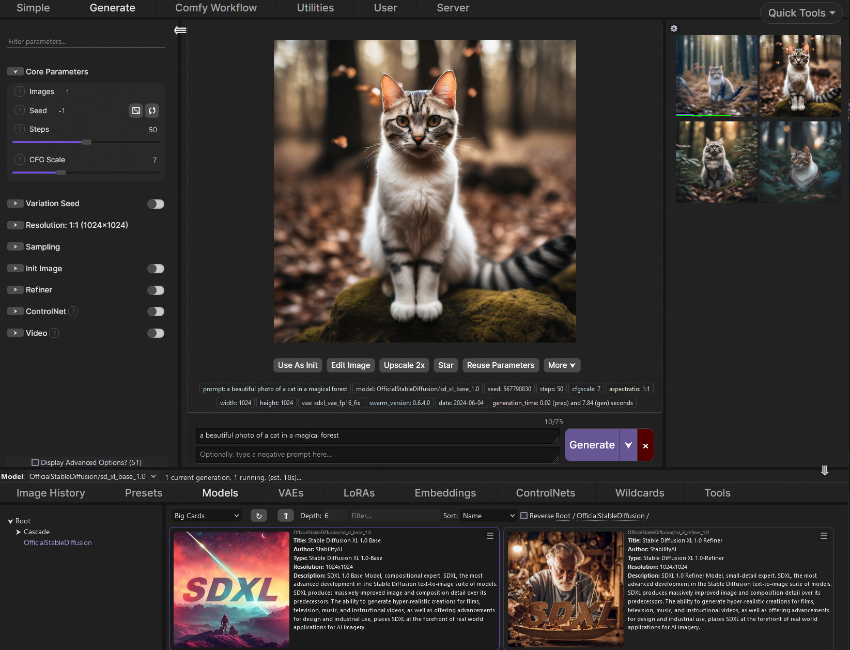
❶整体质量和照片真实感:SD3 Medium模型生成的图像具有出色的细节、色彩和光线处理能力,能够实现照片级别的真实感。通过16通道变分自编码器的技术,模型在处理手部和面部的真实感方面取得了成功。
❷提示理解:模型能够理解并生成包含空间推理、构图元素、动作和风格的复杂和长文本提示。用户可以利用三种文本编码器或它们的组合,以在性能和效率之间做出选择。
❸排版能力:SD3 Medium模型使用Diffusion Transformer架构,显著提高了文本生成的质量,减少了拼写错误、字距不当、字母形状不正确和间距问题。
❹资源高效:模型设计注重资源效率,具有较低的VRAM占用,使其能够在标准消费级GPU上运行而不降低性能。
❺微调能力:SD3 Medium模型能够从小数据集中学习并吸收细节,这使其非常适合进行定制化调整和应用。

Stable Diffusion 3 Medium合作伙伴
❶与NVIDIA合作,利用NVIDIA® RTX™ GPU和TensorRT™提高了所有Stable Diffusion模型的性能。
❷与AMD合作,为SD3 Medium优化了在各种AMD设备上的推理。
Stable Diffusion 3 Medium技术描述
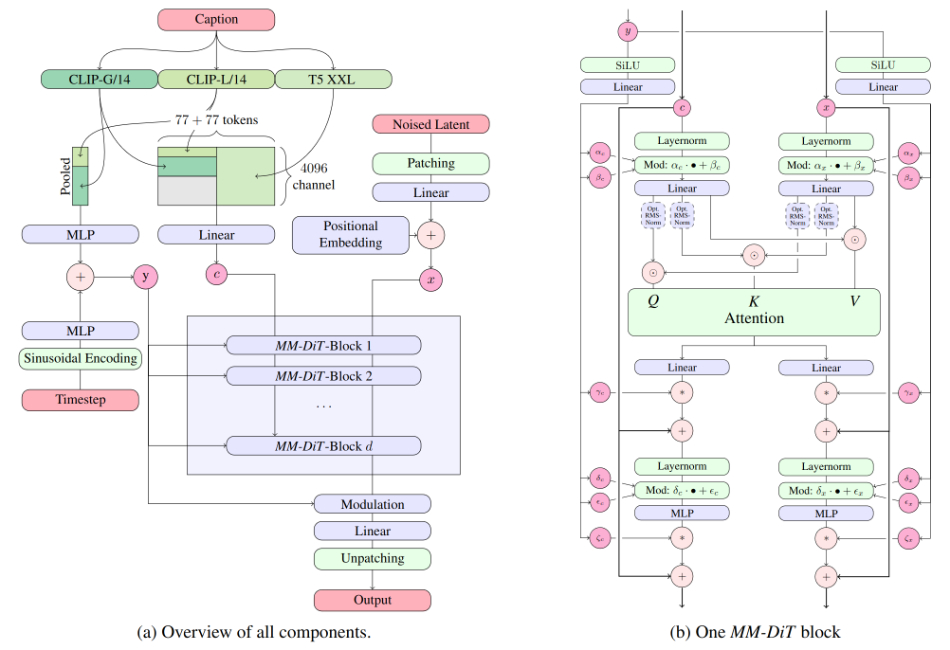
Stable Diffusion 3 Medium是一种多模态扩散变换器 (MMDiT) 文本到图像模型,使用三个固定的、预训练的文本编码器(OpenCLIP-ViT/G、CLIP-ViT/L和T5-xxl)。该模型已在 10 亿张图像上进行了预训练。微调数据包括 3000 万张专注于特定视觉内容和风格的高质量美学图像,以及 300 万张偏好数据图像。有关更多技术细节,请参阅技术报告。
Stable Diffusion 3 Medium相关链接
- 官方介绍主页:https://stability.ai/news/stable-diffusion-3-medium
- GitHub资源:ComfyUI、StableSwarmUI
- arXiv研究论文:https://arxiv.org/abs/2403.03206
- Hugging Face模型下载:https://huggingface.co/stabilityai/stable-diffusion-3-medium

相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号