MotionClone项目简介
MotionClone是由中国科学技术大学、上海交通大学、香港中文大学和上海人工智能实验室的研究人员共同开发的一种创新框架。它允许用户无需训练即可实现从参考视频到文本驱动的视频生成中的动作克隆。这项技术通过时间注意力机制捕捉动作细节,并利用位置感知的语义指导来增强视频的空间合理性和文本对齐度,展现出在全局摄像机运动和局部物体运动控制方面的卓越能力。

MotionClone主要功能
❶训练免费的动作克隆:无需对模型进行训练或微调,即可实现动作的克隆。
❷文本到视频的生成:根据文本提示生成视频,同时将参考视频中的动作应用到新的场景中。
❸全局和局部运动控制:能够处理包括全局摄像机运动和局部物体运动在内的各种复杂动作。
❹动作保真度:保持高动作保真度,确保生成的视频动作与参考视频相似。
❺文本对齐:增强视频内容与文本描述之间的一致性。
MotionClone应用场景
❶数字内容创作:为视频制作和动画设计提供快速动作克隆,简化创作流程。
❷电影和媒体制作:用于特效制作,增强视觉叙事和动作场景的真实感。
❸教育和培训视频:生成与教学内容同步的动作演示,提高学习效果。
❹虚拟现实和增强现实:为虚拟角色或场景提供自然流畅的动作。
❺游戏开发:快速生成游戏内角色动作,加速游戏设计过程。
❻广告制作:创造吸引人的动态广告内容,提升广告吸引力。
❼社交媒体:用户可以生成个性化的动态视频内容分享到社交平台。
MotionClone技术原理
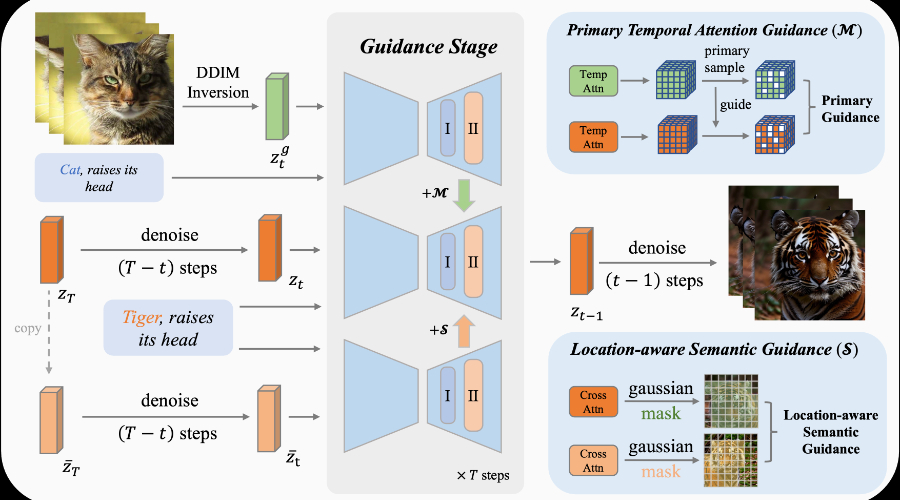
❶时间注意力机制:通过时间注意力层捕捉视频帧之间的时序关系,用于模拟动作。
❷主要时间注意力指导:选择性地利用时间注意力权重中的主要组成部分,以忽略噪声或不重要的动作,专注于主要动作的复制。
❸位置感知的语义指导:利用参考视频中的前景位置信息和原始的分类器自由引导特征,指导视频生成过程中的空间关系和语义内容。
❹视频扩散模型:采用视频扩散模型来编码输入视频并进行潜在表示的采样,以实现视频分布的学习。
❺跨注意力层:使用跨注意力层来提取参考视频和兄弟视频(由文本提示生成的视频)的特征,以增强生成❻视频的语义和空间一致性。
MotionClone项目入口
相关文章











 粤公网安备44011102483711号
粤公网安备44011102483711号