VideoLLaMA 2项目简介
VideoLLaMA 2是由阿里云推出的的一个视频大型语言模型(Video-LLMs),旨在提升视频和音频任务中的空间-时间建模和音频理解能力。该模型通过集成定制的空间-时间卷积(STC)连接器和音频分支,实现了对视频数据中复杂空间和时间动态的有效捕捉,并通过联合训练增强了模型的多模态理解力。在多项视频问答和视频字幕生成任务中,VideoLLaMA 2展现出与开源模型相比的竞争优势,甚至在某些基准测试中接近专有模型的性能,为智能视频分析系统树立了新的标准。
VideoLLaMA 2主要功能
❶视频问题回答:能够理解视频中的内容,并针对提出的问题给出准确的答案。
❷视频字幕生成:自动为视频生成描述性文字,帮助观众更好地理解视频内容。
❸音频理解:通过音频分支,模型能够解析视频中的音频流,并将其与视频内容结合起来提供更丰富的理解。
❹多模态融合:整合视觉和听觉信息,以提供更全面的场景理解,增强对视频和音频数据的综合性分析。
❺空间-时间动态分析:捕捉视频中的空间关系和时间序列变化,以理解事件的发展和物体间的交互。
VideoLLaMA 2模型评估
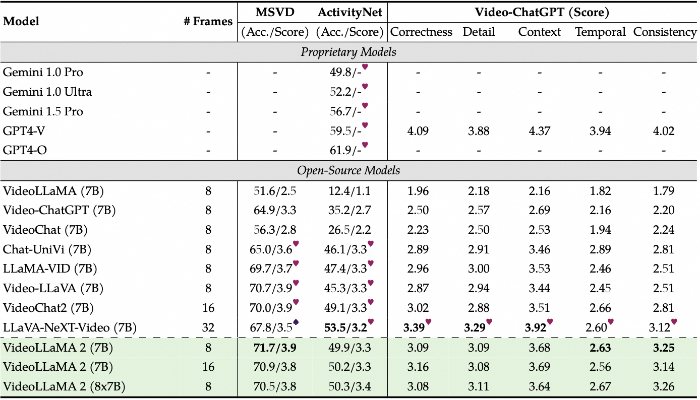
❶多项选择视频问答和视频字幕
 ❷开放式视频问答
❷开放式视频问答
VideoLLaMA 2技术原理
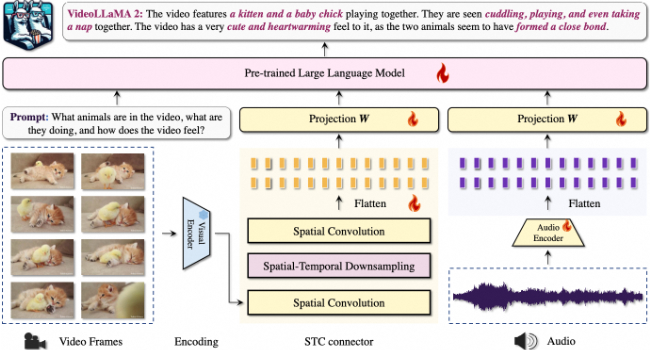
❶空间-时间卷积(STC)连接器:专门设计的模块,用于捕捉视频数据中的空间和时间特征,增强模型对视频帧序列的理解。
❷视觉-语言分支:利用预训练的视觉编码器(如CLIP模型)对视频帧进行编码,然后通过STC连接器处理,将视觉信息转化为适合语言模型处理的格式。
❸音频-语言分支:通过预处理将音频信号转换为频谱图,使用专门的音频编码器(如BEATs)提取音频特征,并通过线性层调整维度,以与语言模型兼容。
❹双分支架构:视频和音频分支独立运作,通过语言模型进行跨模态交互,保留了各自模态输入的完整性,同时促进了模型的扩展性和适应性。
❺联合训练:视频和音频分支通过联合训练进行优化,确保了音频和视觉信息的有效整合,提高了模型对多模态数据的理解和处理能力。
❻大型语言模型(LLM):作为解码器,用于生成文本响应,支持视频语言任务,如问题回答和字幕生成。
❼多任务微调:在预训练的基础上,使用多任务学习对模型进行微调,涉及视频字幕、分类、问答等多个任务,以提高模型在特定领域的性能。
❽跨模态同步:确保视频和音频数据在时间上的同步,以实现精确的多模态分析。
❾多阶段训练:包括预训练、多任务微调和音频-视频联合训练,逐步提升模型对复杂场景的理解和响应能力。
VideoLLaMA 2项目入口
- GitHub源码库:https://github.com/DAMO-NLP-SG/VideoLLaMA2
- arXiv研究论文:https://arxiv.org/abs/2406.07476
- Hugging Face Demo:https://huggingface.co/spaces/lixin4ever/VideoLLaMA2

相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号