Nemotron-4 340B简介
Nemotron-4 340B是由NVIDIA发布的一系列大型语言模型,包括Nemotron-4-340B-Base,Nemotron-4-340B-Instruct和Nemotron-4-340B-Reward三个模型。这些模型在开放许可下提供,允许研究者和开发者自由使用、修改和分发。它们专为高效性能设计,能够在单个DGX H100系统上部署,并在多个评估基准上展现出优异的竞争力。Nemotron-4 340B模型通过合成数据生成和先进的对齐技术,提高了遵循指令、对话交流和问题解决的能力。此外,NVIDIA还开放了模型训练和推理代码,以及合成数据生成管道,进一步促进了AI社区的发展和创新。

Nemotron-4 340B主要功能
❶多任务处理:能够在多种不同的任务上表现出色,包括语言理解、常识推理、数学问题解决和编程等。
❷高质量的指令遵循:特别优化以更好地理解和执行用户的指令,提供准确的响应。
❸有效的对话交流:能够在多轮对话中保持上下文连贯性,实现有效的信息交流和问题解决。
❹合成数据生成:利用模型生成合成数据,以提高预训练数据的质量和多样性,支持模型训练和对齐。
❺开放访问和许可:在NVIDIA开放模型许可协议下提供,允许研究者和开发者自由地进行分发、修改和使用,促进了模型的广泛应用和进一步研究。
Nemotron-4 340B模型评估
❶Nemotron-4 340B-Base:Nemotron-4 340B-Base与Llama-3 70B、Mixtral 8x22B和Qwen-2 72B等其他开放基础模型在常识推理任务如ARC-Challenge、MMLU和BigBench Hard上具有竞争力。
 ❷Nemotron-4 340B-Reward:Nemotron-4 340B-Reward在RewardBench基准测试中取得了最高准确性,甚至超过了如GPT-4o-0513和Gemini 1.5 Pro-0514等专有模型。
❷Nemotron-4 340B-Reward:Nemotron-4 340B-Reward在RewardBench基准测试中取得了最高准确性,甚至超过了如GPT-4o-0513和Gemini 1.5 Pro-0514等专有模型。
 ❸Nemotron-4 340B-Instruct:Nemotron-4 340B-Instruct在指令遵循和聊天能力方面超越了相应的指令模型,如MetaAI的Llama-3 70B-Instruct和Mistral-AI Team的Mixtral-8x22B-Instruct。
❸Nemotron-4 340B-Instruct:Nemotron-4 340B-Instruct在指令遵循和聊天能力方面超越了相应的指令模型,如MetaAI的Llama-3 70B-Instruct和Mistral-AI Team的Mixtral-8x22B-Instruct。
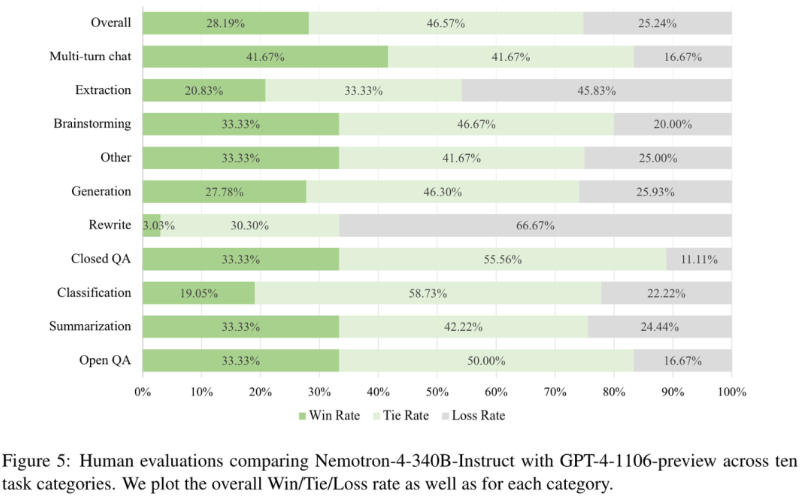
 ❹人类评估:在人类评估中,Nemotron-4 340B-Instruct在多数任务类别中与GPT-4-1106-preview相比展现出可比或更好的表现,特别是在多轮对话任务上。
❹人类评估:在人类评估中,Nemotron-4 340B-Instruct在多数任务类别中与GPT-4-1106-preview相比展现出可比或更好的表现,特别是在多轮对话任务上。
Nemotron-4 340B技术原理
- 预训练与微调:模型在大量高质量数据上进行预训练,之后通过监督式微调(SFT)和偏好微调来提高特定任务的性能。
- Transformer架构:采用标准的仅解码器Transformer模型,利用因果注意力掩码来保证解码时的信息流向正确。
- 旋转位置嵌入(RoPE):使用RoPE来改善模型对序列位置信息的处理能力。
- 合成数据生成管道:开发了一套合成数据生成流程,包括合成提示生成、响应和对话生成、质量过滤和偏好排名,以增强模型的训练数据。
- 迭代弱到强对齐:通过迭代的方式,使用合成数据和对齐训练相互促进,逐步提升模型性能。
- 奖励模型:开发了基于多属性回归的奖励模型,用于评估和指导模型生成的响应质量,是强化学习与人类反馈(RLHF)的核心组件。
- 优化算法:
- 直接偏好优化(DPO):优化模型以最大化选择和拒绝响应之间的隐含奖励差距。
- 奖励感知偏好优化(RPO):在DPO的基础上,进一步考虑奖励的量化差异,以避免过拟合。
- 安全性评估:使用AEGIS等工具进行内容安全风险评估,确保模型输出的安全性和合规性。
- 模型并行和分布式训练:在多个GPU上并行训练模型,使用数据并行、模型并行和流水线并行技术来处理大规模模型。
- 细节优化:包括使用SentencePiece分词器、squared ReLU激活函数、无偏项、零dropout率等细节上的优化,以提高模型效率和性能。
Nemotron-4 340B官方入口
- GitHub源码库:https://github.com/NVIDIA/NeMo-Aligner
- Hugging Face模型:https://huggingface.co/nvidia/Nemotron-4-340B-Base
- 技术报告:https://d1qx31qr3h6wln.cloudfront.net/publications/Nemotron_4_340B_8T_0.pdf
相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号