OpenVLA简介
OpenVLA是由斯坦福大学、加州大学伯克利分校、丰田研究所、谷歌DeepMind等机构的研究人员共同开发的开源视觉-语言-动作模型。这个拥有7亿参数的模型在970k个真实机器人场景上进行了训练,通过结合大规模互联网视觉语言数据和多样化的机器人演示,能够为机器人控制提供强大的预训练策略。OpenVLA支持多机器人控制,并且能够通过高效的微调方法快速适应新的机器人领域,其代码和模型权重完全开源,可在HuggingFace平台下载和微调。

OpenVLA技术特点
❶OpenVLA是一个具有7亿参数的大规模视觉-语言-动作(VLA)模型,它能够处理高维度的数据并学习复杂的任务。
❷模型结合了视觉识别和自然语言处理的能力,使其能够理解视觉场景并根据自然语言指令执行动作。
❸OpenVLA通过在大量互联网视觉语言数据和多样化的机器人演示数据上进行预训练和微调,提高了其在机器人控制任务上的泛化能力。
OpenVLA主要功能
❶支持多机器人系统,能够同时控制多个机器人完成协调任务。
❷通过参数高效的微调方法,OpenVLA能够快速适应新的机器人平台和任务需求。
❸能够理解并执行自然语言描述的任务指令,提高了机器人的交互性和灵活性。
OpenVLA模型架构
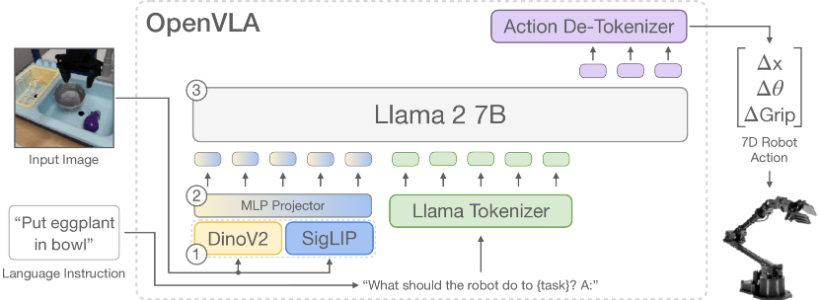
❶视觉编码器(Vision Encoder):这个组件负责将输入的图像转换成一系列的“图像补丁嵌入”(image patch embeddings)。在OpenVLA中,使用了DINOv2和SigLIP两种预训练模型来提取视觉特征,并将这些特征在通道上进行拼接,以增强模型对空间信息的理解能力。
❷投影器(Projector):视觉编码器的输出会被投影器映射到语言模型的输入空间。这一步骤是通过一个小型的多层感知机(MLP)实现的,它将视觉特征从视觉编码器的输出空间映射到语言模型的嵌入空间。
❸大型语言模型(Large Language Model, LLM)主干:这是OpenVLA的核心,一个大型的预训练语言模型,用于处理语言任务。在OpenVLA中,使用了Llama 2,这是一个7B参数的大型语言模型,作为VLA的背部结构。
❹动作预测:OpenVLA将连续的机器人动作映射到离散的标记(tokens)上,这些标记被用于语言模型的分词器。模型通过训练学习将输入的图像和自然语言任务指令映射到一系列预测的机器人动作标记上。
❺训练过程:在训练OpenVLA时,使用了从Open X-Embodiment数据集中提取的970k个真实世界的机器人演示。这些数据涵盖了多种机器人形态、任务和场景,使得OpenVLA能够控制多种机器人,并且可以通过微调快速适应新的机器人设置。
❻微调策略:OpenVLA支持多种微调策略,包括全参数微调、仅微调最后一层、冻结视觉编码器、三明治微调和使用低秩适应技术(LoRA)等,以提高计算效率并减少对计算资源的需求。
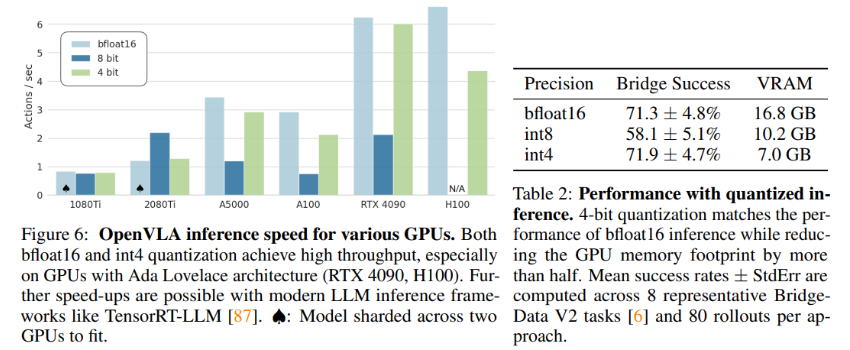
❼量化:为了提高推理效率,OpenVLA还支持模型量化,这可以减少模型在推理时所需的GPU内存,同时保持性能。
OpenVLA实验评估
❶多机器人平台的直接评估结果:在WidowX和Google机器人平台上,OpenVLA在视觉、运动、物理和语义泛化任务上进行了测试。结果显示,在这些任务中,OpenVLA的平均成功率达到了70.6%,这个数字是在进行了170次试验后得出的。

❷参数高效微调的策略结果:使用低秩适应(LoRA)技术进行微调时,OpenVLA在仅微调了模型1.4%的参数后,其性能与全参数微调相当。在具体的实验中,LoRA微调后的OpenVLA在某些任务上的成功率达到了68.2%,与全参数微调的性能相当。

❸内存高效推理的实现结果:通过4位量化技术,OpenVLA在推理时的GPU内存需求减少了一半以上,同时保持了与半精度(bfloat16)推理相似的性能。具体来说,在BridgeData V2任务上,4位量化的OpenVLA模型仍然能够达到71.3%的成功率。
❹与现有技术的比较结果:在与RT-2-X模型的比较中,OpenVLA在29项任务上显示出了16.5%的绝对成功率提升。这意味着在相同的测试条件下,OpenVLA的成功率为70.6%,而RT-2-X的成功率为54.1%(基于OpenVLA的成功率减去16.5%)。
OpenVLA项目入口
- 官方项目主页:https://openvla.github.io/
- GitHub源码库:https://github.com/openvla/openvla
- arXiv研究论文:https://arxiv.org/abs/2406.09246v1
- Hugging Face模型:https://huggingface.co/openvla
相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号