VividPose项目简介
VividPose是一项由复旦大学和腾讯优图实验室联合开发的先进技术,它利用稳定视频扩散(Stable Video Diffusion, SVD)模型,实现了从静态图片到逼真动态视频的高效转换。这项技术通过身份意识外观控制器和几何意识姿势控制器,确保了动画在不同姿态下保持人物身份的高保真度和动态手势的准确性,显著提升了视频生成的质量和自然度。

VividPose主要功能
❶身份意识外观控制:通过额外的面部信息增强人物身份特征的保留,确保不同姿态下关键面部特征的一致性。
❷几何意识姿势控制:结合SMPL-X模型的密集渲染图和2D姿势估计器的稀疏骨架图,实现对多样化人体形状和手势的精确对齐和动画生成。
❸端到端流程:提供一个连贯的框架,从静态图像到动态视频的生成过程中,保持高视觉保真度和处理复杂动态的能力。
❹时间稳定性:利用稳定视频扩散模型,提高生成视频的时间连贯性,减少帧间抖动和不一致性。
VividPose应用场景
❶社交媒体:创建个性化和吸引人的动态内容。
❷电影和娱乐:生产逼真的角色动画。
❸在线零售:通过动画化的模特展示服装试穿效果。
❹虚拟现实:提供更加真实的虚拟角色和环境互动。
VividPose技术原理
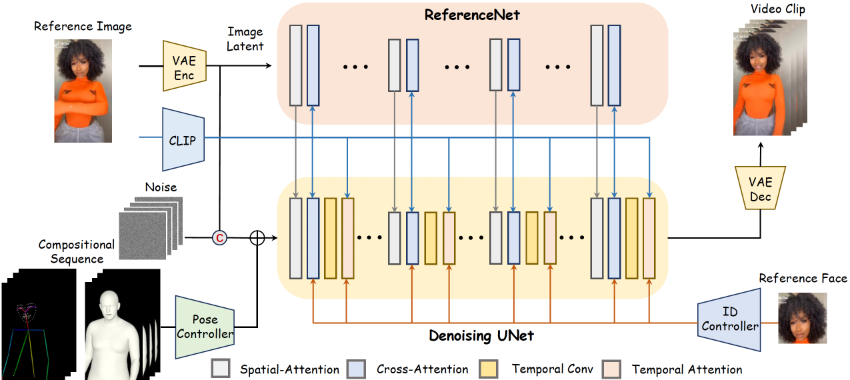
❶稳定视频扩散(SVD):一种先进的视频生成模型,通过3D卷积和时间注意力层来处理视频数据,实现高分辨率和时间一致的视频生成。
❷SMPL-X模型:一个3D参数化人体模型,通过形状、姿势和表情参数控制,用于生成与参考图像一致的2D渲染图。
❸多尺度特征编码:使用ReferenceNet和CLIP技术对参考图像进行多尺度特征编码,并通过空间自注意力机制整合到去噪UNet中。
❹面部身份特征编码:使用ArcFace技术提取面部特征,并将其通过解耦的交叉注意力机制注入到UNet中,增强面部特征的保留。
❺零卷积融合:在编码器的末端使用零卷积层,以最小化对SVD生成能力的干扰,并将融合的特征添加到噪声潜在空间中。
❻骨架图和渲染图的结合:使用轻量级编码器分别对骨架图和渲染图进行编码,并通过求和融合这些特征,以实现精确的身体形状和动态手势的对齐。
VividPose项目入口
- 官方项目主页:https://kelu007.github.io/vivid-pose/
- GitHub源码库:https://github.com/Kelu007/VividPose
- arXiv研究论文:https://arxiv.org/pdf/2405.18156v1

相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号