DriveVLM简介
DriveVLM是由清华大学IIIS实验室与Li Auto公司联合开发的一项创新自动驾驶系统。该系统融合了先进的视觉语言模型(VLMs),通过独特的思维链(Chain-of-Thought)模块,显著提升了对复杂城市环境场景理解和规划的能力。DRIVEVLM不仅优化了场景描述、分析和分层规划,还通过提出DRIVEVLM-Dual混合系统,克服了传统VLMs在空间推理和计算需求上的局限性,实现了强大的空间理解和实时推理速度,为自动驾驶领域带来了突破性进展。

DriveVLM主要功能
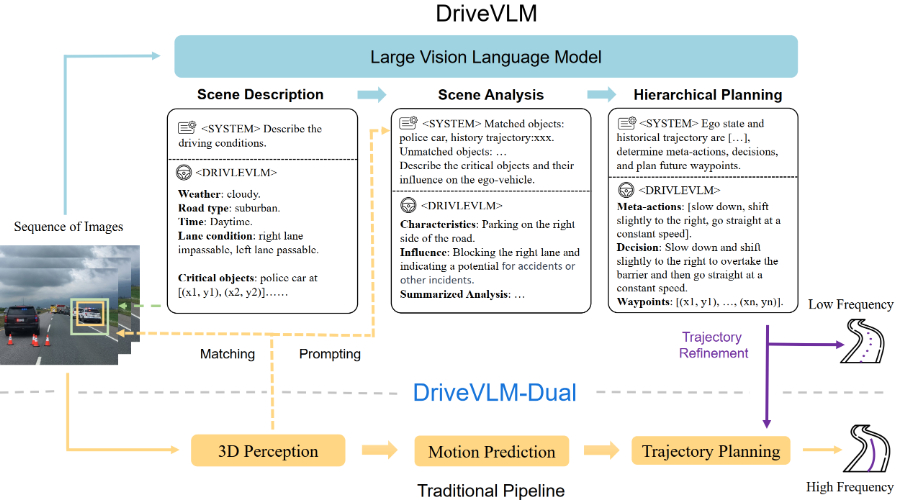
❶场景描述:使用环境描述和关键对象识别来语言化描述驾驶环境。
❷场景分析:深入分析关键对象的特性及其对自车的影响,包括静态属性、运动状态和特殊行为。
❸分层规划:结合场景描述和分析,逐步生成从宏观动作到决策描述再到路径点的详细驾驶计划。
❹混合系统:DRIVEVLM-Dual结合了传统自动驾驶管道的优势,实现了3D空间理解和高频规划能力。
DriveVLM技术原理
❶视觉语言模型(VLMs):集成预训练的视觉编码器和大型语言模型,通过监督微调使用图像和文本的指令数据来提升性能。
❷思维链(CoT)机制:通过CoT推理,将视觉信息与语言模型相结合,进行复杂的视觉理解和推理。
❸关键对象分析:专注于识别和分析对当前场景影响最大的对象,而非检测所有对象。
❹3D感知集成:使用3D检测器的结果作为语言提示,提高对关键对象位置和运动状态的精确理解。
❺高频轨迹细化:与常规规划器结合,实现高频、实时的轨迹规划和优化。
❻数据挖掘与注释流程:构建专门的SUP-AD数据集,包含多样化的复杂和长尾场景,用于模型训练和评估。
DriveVLM应用场景
❶城市道路驾驶:在复杂的城市交通环境中,DRIVEVLM能够理解和应对多变的道路条件和行人行为。
❷高速公路巡航:在高速公路上,系统可以进行高效的轨迹规划,以适应高速行驶的需求。
❸交通拥堵处理:在交通拥堵的情况下,DRIVEVLM能够分析周围车辆的动态并做出合理的驾驶决策。
❹异常情况响应:面对紧急情况,如交通事故或道路施工,系统能够迅速识别并规划安全绕行路径。
❺多模式交通环境:在包含行人、自行车、摩托车和各种车辆的混合交通环境中,DRIVEVLM能够理解和预测不同交通参与者的行为。
❻夜间或恶劣天气驾驶:系统能够适应夜间或雨、雪、雾等恶劣天气条件,提供可靠的驾驶支持。
❼长尾场景处理:对于不常见的交通场景,如罕见物体或特殊事件,DRIVEVLM能够利用其视觉语言模型进行有效的理解和响应。
❽交互式驾驶辅助:DRIVEVLM可以通过自然语言接口与驾驶员或乘客进行交互,提供更加个性化的驾驶辅助。
❾自动驾驶测试与验证:在自动驾驶技术的研发和测试阶段,DRIVEVLM可以作为一个强大的工具来验证和提升系统性能。
❿车队管理和自动驾驶出租车服务:在车队运营和自动驾驶出租车服务中,DRIVEVLM可以提供一致和可靠的驾驶策略,以确保乘客安全和运营效率。
DriveVLM项目入口

相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号