LLM Compiler简介
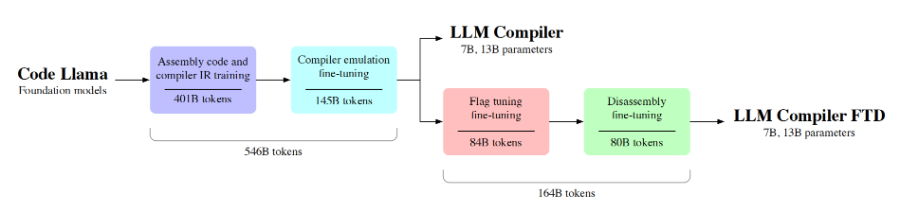
LLM Compiler(Large Language Model Compiler)是由Meta最新推出的大型语言模型编译器,专为代码优化任务设计。它基于Code Llama模型,通过在546亿个LLVM-IR和汇编代码上的训练,显著提升了对编译器中间表示和汇编语言的理解能力。LLM Compiler以7亿和13亿参数的两种规模提供,支持广泛的重用,并在优化代码尺寸和从汇编代码反汇编到LLVM-IR的任务中展现出卓越的性能。该工具旨在为学术界和工业界的研究人员和实践者提供一个可扩展、成本效益高的编译器优化研究和开发基础。

LLM Compiler主要功能
❶代码优化:LLM Compiler能够对代码进行优化,以提高性能和减少资源消耗。
❷编译器IR理解:专门设计用于理解编译器中间表示(IRs),这是编译过程中的一个关键步骤。
❸汇编语言优化:能够处理和优化汇编语言,这是最接近硬件的编程语言。
❹自动调优:具备自动调整编译器标志的能力,以优化代码尺寸和性能。
❺反汇编能力:可以将汇编代码转换回LLVM-IR,有助于代码分析和架构迁移。
❻多任务微调:经过微调,能够执行多种编译相关任务,包括但不限于代码优化和反汇编。
❼商业和研究适用:适用于商业和研究领域,提供灵活的许可选项以支持广泛的应用场景。
LLM Compiler技术原理
❶预训练模型基础:基于Code Llama等预训练语言模型,这些模型已经在大量代码数据上进行了训练,具备良好的代码理解能力。
❷大规模数据训练:在包含546亿个token的LLVM-IR和汇编代码的大规模数据集上进行训练,增强了模型对编译器IR和汇编语言的理解。
❸指令微调:通过指令微调,模型学习如何根据编译器优化指令预测代码优化的结果。
❹自回归Transformer架构:采用自回归Transformer架构,能够基于给定的上下文生成最优的代码序列。
❺长序列上下文学习:支持长达16K tokens的上下文长度,使模型能够处理较长的代码段,进行更深入的分析和优化。
❻多阶段训练流程:包括预训练、编译器特定数据的微调和针对特定下游任务的微调,逐步提升模型在特定任务上的性能。
❼编译器仿真:通过模拟编译器优化过程,生成优化后的代码样本,用于训练和评估模型。
❽自动调优算法:开发了自动化的调优算法,通过迭代搜索最优的编译器标志组合来最小化代码尺寸。
❾反汇编技术:利用机器学习技术将汇编代码映射回高级IR,支持代码的逆向工程和跨平台迁移。
❿商业许可和社区协作:通过定制的商业许可,鼓励社区协作和模型的广泛重用,同时确保合规使用。
LLM Compiler评估结果
❶优化潜力:LLM Compiler在优化任务中表现出色,能够实现与自动调优搜索相媲美的优化效果,达到了77%的优化潜力。
❷反汇编能力:在将x86_64和ARM汇编代码重新组装回LLVM-IR的任务中,LLM Compiler的微调版本能够以14%的准确率进行正确的反汇编,其中77%的结果是部分正确的。
❸标志调整任务:在标志调整任务中,LLM Compiler能够为LLVM的IR优化工具opt选择标志,以产生最小的代码尺寸。在零样本学习(zero-shot)情况下,LLM Compiler预测的标志能够改善代码尺寸,与基线相比有所提升。
❹编译器仿真任务:在编译器仿真任务中,LLM Compiler经过特定阶段的训练后,能够生成可编译的IR或汇编代码,并且有一定比例的代码与编译器实际产生的代码完全匹配。
❺代码尺寸预测准确性:LLM Compiler在预测优化前后的代码尺寸方面表现出较高的准确性,模型生成的预测与实际结果有很好的相关性。
❻软件工程任务:尽管LLM Compiler主要针对编译优化任务进行了训练,但其在基础的软件工程任务,如Python编程任务中,也展现出了一定的能力,尽管这些能力随着编译器中心训练的增加而略有下降。
❼性能比较:与其他模型(如Code Llama和GPT-4 Turbo)相比,LLM Compiler在编译优化任务中表现出显著的优势,尤其是在标志调整和反汇编任务中。
❽模型大小影响:评估还考虑了模型大小对性能的影响,发现较大尺寸的模型(13B参数)在某些任务上略微优于较小尺寸的模型(7B参数)。
❾训练阶段的影响:通过逐步增加训练阶段,评估了不同训练阶段对模型性能的影响,发现特定训练阶段如反汇编训练对某些任务的性能有积极影响,而对其他任务则可能略有负面影响。
LLM Compiler官方入口

相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号