FunAudioLLM简介
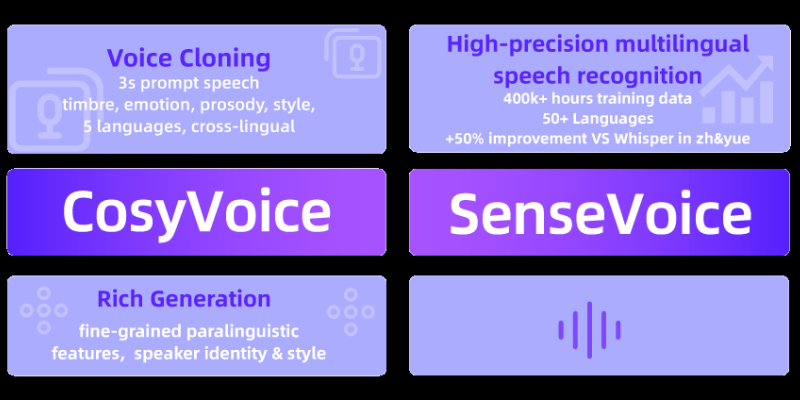
FunAudioLLM是由阿里通义团队发布的一款先进的语音理解和生成模型家族,旨在提升人类与大型语言模型(LLMs)之间的自然语音交互体验。它包含两个核心模型:SenseVoice,负责高精度的多语言语音识别、情绪识别和音频事件检测;以及CosyVoice,专注于多语言的自然语音生成,提供对音色、说话风格和说话者身份的精细控制。FunAudioLLM通过开源模型和代码,支持创新应用如语音翻译、情感聊天、互动播客和有声读物,推动了语音交互技术的边界。
FunAudioLLM
FunAudioLLM主要功能
多语言语音识别:支持超过50种语言的高精度自动语音识别(ASR),特别是中文和粤语。
情绪识别:能够识别语音中的情绪状态,为交互增添情感维度。
音频事件检测:识别音频中的特定事件,如音乐、掌声和笑声。
多语言语音生成:生成多种语言的自然语音,支持特定说话者的风格。
零样本学习:无需训练即可适应新说话者的声音,实现跨语言的声音克隆。
情感语音生成:根据文本指令生成具有特定情绪色彩的语音。
语音交互应用:支持语音到语音翻译、情感语音聊天、互动播客和有声读物等应用。
FunAudioLLM技术原理
非自回归架构:SenseVoice-Small采用非自回归编码器架构,实现快速处理和低延迟。
编码器-解码器模型:SenseVoice-Large使用编码器-解码器模型,通过序列输入标记来指定任务,提高识别精度和语言支持。
端到端架构:CosyVoice采用端到端架构,直接从文本到语音,减少中间步骤,提高效率。
监督语义语音分词器(S3):基于预训练的SenseVoice-Large模型,结合向量量化器,生成与语义内容强相关的离散化语音标记。
基于ODE的流匹配:使用基于常微分方程的流匹配模型从生成的语音标记重建梅尔频谱。
HiFTNet声码器:用于从重建的梅尔频谱合成波形,支持流式生成。
零样本上下文学习:CosyVoice能够通过简短的参考语音样本实现任意声音的复制。
指令微调:CosyVoice-instruct模型通过指令微调增强了对各种语音特征的控制能力,如说话者身份、情绪、语速和音调。
多任务学习:模型训练时同时优化语言识别、情绪识别和音频事件检测任务,提高模型的多任务处理能力。

FunAudioLLM应用场景
语音翻译:实现不同语言之间的即时语音翻译。
情感聊天机器人:提供能识别和表达情绪的对话体验。
有声读物:生成具有丰富情感和表现力的有声书籍。
播客制作:自动化生成多角色、多情感的播客内容。
客户服务:自动化客户支持热线,提供自然语音交互。
语言学习:辅助语言学习,提供标准或特定口音的发音示例。
辅助技术:为视障或阅读困难者提供语音读取服务。
智能家居控制:通过语音命令控制家中智能设备。
会议记录:自动记录并转写会议内容,提供多语言支持。
虚拟助手:提供个性化的语音助手,执行日常任务和提醒。
FunAudioLLM项目入口
- 官方项目主页:https://fun-audio-llm.github.io/
- GitHub源码库:https://github.com/FunAudioLLM
- arXiv研究论文:https://fun-audio-llm.github.io/pdf/FunAudioLLM.pdf
- 在线使用SenseVoice:https://www.modelscope.cn/studios/iic/SenseVoice
- 在线使用CosyVoice:https://www.modelscope.cn/studios/iic/CosyVoice-300M

相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号