Image Textualization简介
Image Textualization 是由香港科技大学、武汉大学、浙江大学和伊利诺伊大学香槟分校的联合研究团队开发的一项创新技术。这项技术通过结合多模态大型语言模型(MLLMs)和视觉专家模型,自动化地生成高质量、详细的图像描述。它旨在解决现有图像描述数据集存在的质量参差不齐和细节不足的问题,为图像理解、文本到图像生成和图像检索等领域提供更丰富、准确的视觉信息文本化服务。通过这一框架,研究团队成功提升了图像描述的准确性,减少了幻觉现象,并为机器学习模型提供了更优质的训练数据。
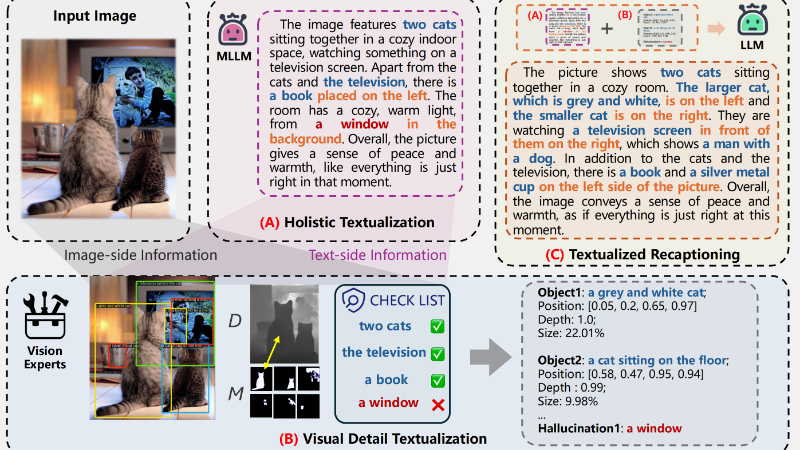
Image Textualization
Image Textualization主要功能
❶自动化图像描述生成:能够自动创建图像的文本描述,无需人工干预。
❷高质量文本输出:利用先进的语言模型,生成的描述质量高,细节丰富。
❸减少幻觉现象:相较于传统的MLLMs,IT生成的描述中减少了视觉幻觉的出现。
❹多模态协作:结合了多模态大型语言模型(MLLMs)和视觉专家模型的优势。
❺数据集构建:IT可用于生成大规模的高质量图像描述数据集,支持机器学习模型的训练和评估。
Image Textualization技术原理
- 整体文本化(Holistic Textualization):使用MLLM生成基本的参考描述,为后续的细节添加和幻觉检测提供基础结构。
- 视觉细节文本化(Visual Detail Textualization):利用视觉专家模型提取图像中的细粒度对象级信息,并将其转换为文本格式。
- 幻觉检测(Hallucination Detection):通过实体提取和开放集对象检测器识别参考描述中的幻觉内容,并将其标记为删除。
- 密集描述生成(Dense Caption Generation):使用密集描述模型识别图像中可能在原始描述中缺失的对象,并生成详细的描述。
- 空间信息收集(Spatial Information Collection):通过单目深度估计和对象分割掩码获取对象的深度和大小信息,增强描述的三维空间感。
- 文本化重描述(Textualized Recaptioning):利用LLMs根据前两阶段转换而来的文本信息重新生成图像描述,确保描述的准确性和细节丰富性。
- 评估基准构建:创建了包括DID-Bench、D2I-Bench和LIN-Bench在内的评估基准,用于全面评估生成描述的质量。

Image Textualization
Image Textualization应用场景
❶ 社交媒体内容生成:自动为图片添加描述,增强用户互动。
❷电子商务:提供产品图片的详细描述,改善购物体验。
❸安全监控:自动分析监控图像,快速识别异常事件。
❹辅助视觉:为视障人士提供图像内容的语音描述。
❺教育辅助:在数字教材中自动生成图像描述,辅助学习。
❻版权管理:帮助识别和描述图像内容,便于版权追踪。
❼新闻报道:自动生成新闻图片的描述,提高编辑效率。
❽艺术展览:为艺术作品生成详细的背景描述。
❾旅游推荐:自动描述景点图片,提供丰富的旅游信息。
❿智能家居:识别家庭环境中的图像并提供相关描述或提醒。
Image Textualization项目入口

相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号