MiraData简介
MiraData是由腾讯和香港中文大学的研究团队共同开发的大型视频数据集。该数据集以其长时视频和结构化字幕而著称,专门为生成具有高运动强度和一致性的视频而设计。它通过从多样的精选源中手动收集视频,并通过细致的处理确保了片段之间的语义连贯性。MiraData利用先进的GPT-4V模型进行细致的字幕注释,提供了从不同角度出发的详尽描述,包括密集字幕和结构化字幕。此外,为了全面评估视频生成的质量,团队还引入了MiraBench,这是一个增强型评估基准,包括一系列覆盖多个方面的指标,如时间一致性、3D一致性等。

MiraData主要功能
❶ 高质量视频数据集提供:MiraData提供了一个大规模的高质量视频数据集,这些视频具有较长的持续时间和丰富的结构化字幕。
❷长视频生成支持:数据集特别设计用于支持生成具有高运动强度和长持续时间的视频。
❸结构化字幕注释:使用GPT-4V模型为视频生成详细的结构化字幕,包括短字幕、密集字幕和从不同角度的描述。
❹视频质量与运动强度评估:通过MiraBench基准测试,提供了一系列评估指标来衡量视频生成模型的性能,特别是视频质量和运动强度。
❺时间一致性和3D一致性评估:MiraBench包括评估视频生成中时间连贯性和3D空间连贯性的指标。
MiraData技术原理
❶数据收集与筛选:从YouTube、Videvo、Pixabay和Pexels等平台手动选择视频源,确保视频的多样性和质量,并通过特定的标准筛选视频片段。
❷视频分割与拼接:使用多种模型来检测视频内容的连贯性,将长视频分割成语义上一致的片段,并通过模型确定是否将相邻片段连接起来。
❸ 高质量片段选择:根据美学、运动强度和色彩等标准,从数据集中筛选出具有高视觉质量和强烈运动强度的片段。
❹字幕生成与注释:首先使用现有的字幕生成模型创建简短字幕,然后利用GPT-4V模型丰富这些字幕,生成包含多个视角描述的密集和结构化字幕。
❺评估基准MiraBench:开发了一个包含150个评估提示和17个指标的评估套件,用于全面评估视频生成模型在多个方面的表现,包括时间一致性、运动强度、3D一致性、视觉质量和文本-视频对齐。
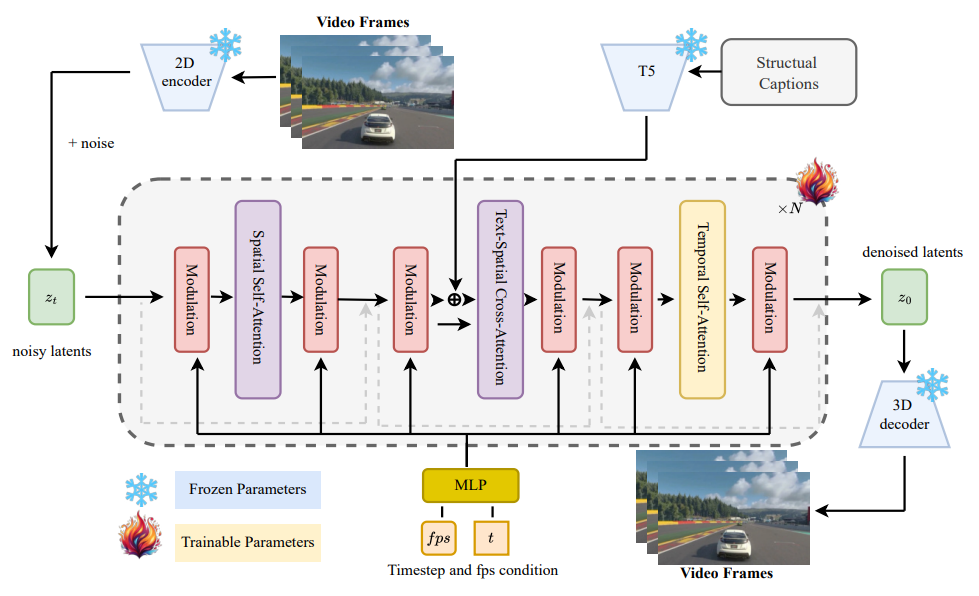
❻视频生成模型MiraDiT:基于Diffusion Transformer设计了一个高效的视频生成模型,支持不同分辨率和长度的视频生成,并在生成过程中控制运动强度。
MiraData适用人群
❶视频生成模型开发者:需要大规模、高质量的视频数据集来训练和测试他们的视频生成算法。
❷计算机视觉研究人员:专注于视频内容分析、视频理解和视频处理的学者和研究人员。
❸人工智能工程师:在AI领域工作,特别是那些专注于生成模型、机器学习和深度学习的专业人士。
❹多媒体内容创作者:利用视频生成技术来创造新的或者增强现有视频内容的艺术家和设计师。
❺教育和学术机构:用于教学目的,帮助学生理解视频处理和生成模型的工作原理。
❻行业分析师和决策者:需要评估视频生成技术在特定行业中的应用潜力和市场趋势。
❼数据科学家:对大规模视频数据分析感兴趣,希望利用这些数据进行模式识别、趋势预测等。
❽伦理和技术政策制定者:关注视频生成技术可能带来的社会影响,制定相关政策和指导原则。
MiraData项目入口
- 官方项目主页:https://mira-space.github.io/
- GitHub代码库:https://github.com/mira-space/MiraData
- arXiv研究论文:https://arxiv.org/abs/2407.06358v1
相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号