H2O Danube3项目简介
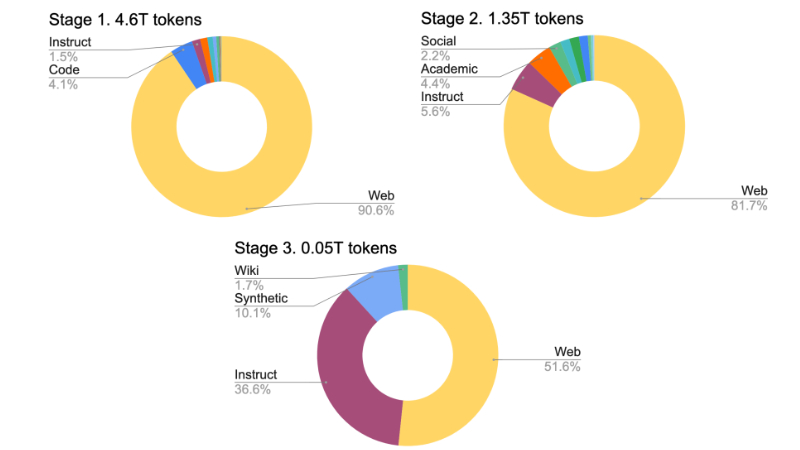
H2O-Danube3是由H2O.ai开发团队推出的一系列高效能小型语言模型,包括4B和500M两个参数规模的版本。这些模型经过三阶段的高质量网络数据预训练和精细的监督微调,具备出色的学术、聊天和微调基准测试表现。H2O-Danube3的设计注重在现代智能手机等移动设备上的本地推理和快速处理能力,使得其在多种应用场景中具有广泛的实用性。该系列模型已在Apache 2.0许可下全面开源,进一步推动了大型语言模型技术的普及和应用。
H2O Danube3主要功能
❶高效推理:H2O-Danube3设计用于在现代智能手机和边缘设备上进行高效推理,支持本地处理和快速响应。
❷多任务处理:适用于多种语言处理任务,包括但不限于序列分类、问答、文本分类和标记分类。
❸聊天机器人应用:经过特别优化,适合用于聊天机器人,能够处理多轮对话和提供自然语言交互。
❹微调能力:可以针对特定任务进行微调,优化模型在特定数据集上的表现。
❺开源可访问:在Apache 2.0许可下开源,使得开发者和研究人员可以自由地访问和使用这些模型。
❻模型量化:提供量化版本的模型,减少模型大小,同时保持较高的性能,适合在资源受限的设备上运行。
H2O Danube3模型架构
- 解码器架构:H2O-Danube3是一系列仅解码器(decoder-only)的大规模语言模型(LLM),这意味着它们专注于生成文本而不是编码输入。
- Llama模型架构:H2O-Danube3采用了Llama模型架构的核心原则,这是一种高效的语言模型设计,旨在提高模型的计算效率和参数效率。
- Mistral分词器:模型使用Mistral分词器,支持32,000的词汇量,这使得模型能够处理丰富的语言内容。
- Grouped Query Attention:模型采用了Grouped Query Attention机制,这是一种注意力机制的优化,有助于提高模型的参数和计算效率。
- 多层结构:
- H2O-Danube3-4B模型包含24层,而H2O-Danube3-500M模型包含16层。
- 每层的隐藏尺寸分别为3840和1536,中间尺寸分别为10240和4096。
- 多头注意力机制:
- H2O-Danube3-4B模型有32个注意力头,而H2O-Danube3-500M模型有16个注意力头。
- 每个注意力头的大小分别为120和96。
- 参数数量:
- H2O-Danube3-4B模型包含约39.6亿个可训练参数。
- H2O-Danube3-500M模型包含约5亿个可训练参数。
- 上下文长度:模型能够处理的上下文长度高达8192,这使得它们能够理解和生成更长的文本序列。
- RoPE theta:模型使用了RoPE(相对位置编码)技术,theta参数分别为100000,这有助于模型捕捉文本中的长距离依赖关系。
- 量化版本:为了在边缘设备上使用,H2O-Danube3还提供了不同量化级别的模型版本,如4位、3位等,以减少模型大小并适应不同的计算环境。
H2O Danube3应用场景
❶聊天机器人:可以用于构建智能聊天机器人,提供自然语言交互体验。
❷ 文本分类:在需要文本内容分类的场景中,如垃圾邮件检测、情感分析等。
❸问答系统:用于构建问答系统,能够理解和回答用户的问题。
❹内容生成:在需要自动生成文本内容的场合,如新闻文章、社交媒体帖子等。
❺语言翻译:可以辅助进行语言翻译,提高翻译的准确性和流畅性。
❻教育工具:作为辅助教学的工具,帮助学生学习和练习语言。
❼医疗咨询:在医疗领域,辅助医生和患者进行沟通,提供医疗咨询。
❽企业自动化:帮助企业自动化处理文档、报告和通信,提高工作效率。
❾移动应用:在移动设备上提供本地化的智能服务,如个人助理应用。
❿边缘计算:在资源受限的设备上运行,如智能家居设备、工业自动化设备等。
H2O Danube3项目入口

相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号