IMAGDressing-v1简介
IMAGDressing-v1是由南京理工大学联合华为公司、腾讯AI实验室和南京大学的研究人员共同开发的一项创新技术。这项技术通过结合先进的服装UNet和去噪UNet,利用CLIP和VAE提取服装的语义和纹理特征,实现了高度逼真的虚拟试衣体验。它不仅支持通过文本提示控制不同场景,还能与ControlNet和IP-Adapter等插件结合使用,增强生成图像的多样性和可控性。此外,为了解决数据不足的问题,开发团队还发布了包含超过30万对服装和穿着图像的IGPair数据集,为虚拟试衣技术的研究和应用提供了宝贵的资源。
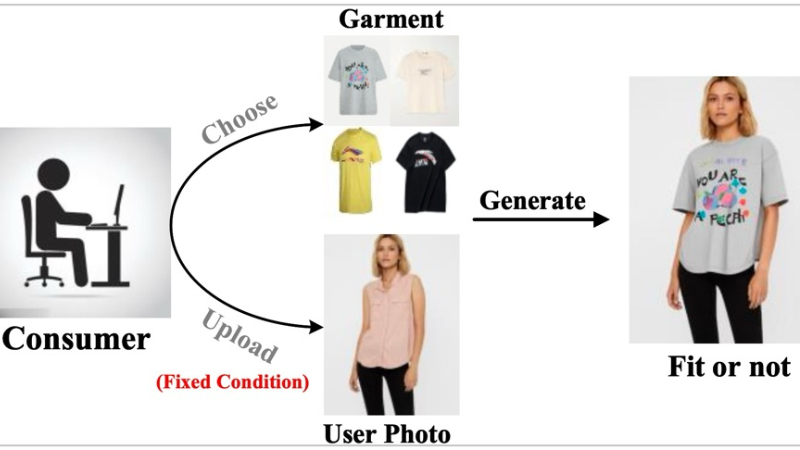
IMAGDressing-v1主要功能
❶自由编辑的人体图像生成:能够生成具有固定服装和可选条件(如面孔、姿势和场景)的可编辑人体图像。
❷服装特征整合:通过服装UNet捕获服装的语义和纹理特征,确保服装细节在生成的图像中得以保留。
❸场景控制:用户可以通过文本提示控制生成图像的不同场景,实现个性化的虚拟试衣体验。
❹插件兼容性:支持与其他扩展插件(如ControlNet和IP-Adapter)结合使用,增强图像的多样性和控制性。
❺数据集支持:提供了IGPair数据集,包含大量服装和穿着图像,支持研究者进行数据驱动的研究和开发。
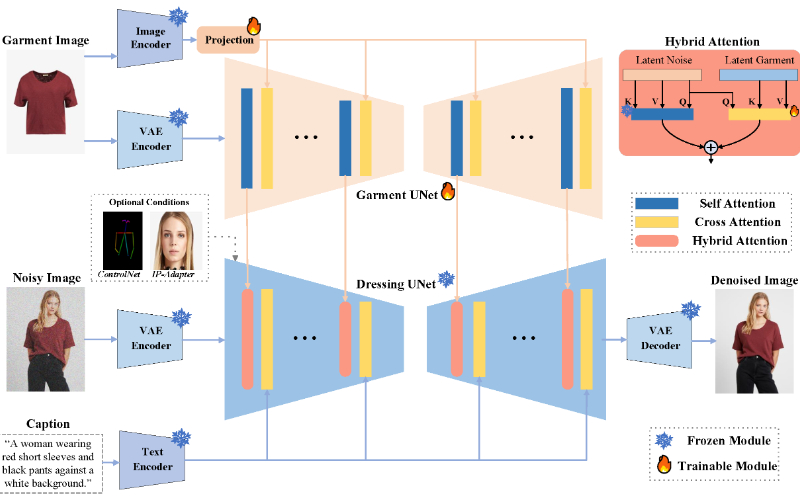
IMAGDressing-v1技术原理
❶服装UNet:一个训练有素的网络,用于从服装图像中提取语义特征和纹理特征,这些特征随后用于指导图像生成过程。
❷去噪UNet:一个冻结的网络,用于在潜在空间中进行去噪处理,以生成高质量的图像。
❸混合注意力模块:包含冻结的自注意力和可训练的交叉注意力,用于整合来自服装UNet的服装特征,并根据文本提示进行场景控制。
❹潜在扩散模型:一种用于文本到图像生成的模型,通过多步去噪过程生成特定个体穿着目标服装的图像。
❺综合亲和度指标(CAMI):一种评估生成图像与参考服装一致性的指标,包括未指定条件和指定条件下的评分。
❻自动化和手动数据收集:通过自动化工具和手动验证相结合的方式,收集和整理了大规模的服装配对数据集。
❼文本特征编码:使用CLIP文本编码器将文本提示转换为可以用于图像生成的标记嵌入。
图像和文本的融合:通过混合注意力机制,将文本特征和图像特征结合,以生成符合文本描述的图像。
IMAGDressing-v1应用场景
❶电子商务平台:在线商店使用IMAGDressing-v1展示服装在不同模特上的效果。
❷个性化推荐:根据用户身材和偏好,推荐适合的服装款式和搭配。
❸时尚设计:设计师利用该技术快速预览服装设计在不同体型上的效果。
❹社交媒体:用户在社交平台上分享自己虚拟试穿服装的照片或视频。
❺虚拟时尚秀:在没有实体服装的情况下,通过虚拟试衣展示最新时尚趋势。
❻游戏和虚拟现实:在游戏中或虚拟现实环境中为角色定制服装和外观。
IMAGDressing-v1项目入口
- 官方项目主页:https://imagdressing.github.io/
- GitHub代码库:https://github.com/muzishen/IMAGDressing
- arXiv研究论文:https://arxiv.org/pdf/2407.12705
相关文章












 粤公网安备44011102483711号
粤公网安备44011102483711号