CogVideoX:智谱AI开源的视频生成模型(新增CogVideoX-5B模型)
CogVideo简介
CogVideoX是由智谱AI推出的一款先进的文本到视频扩散模型。是 清影 同源的开源版本视频生成模型。它通过结合3D变分自编码器和专家变换器架构,能够高效地生成具有高度一致性和显著动态效果的长时视频。CogVideoX通过精心设计的数据预处理和视频字幕方法,显著提升了视频生成的质量和语义对齐度。此外,该模型采用混合时长训练和分辨率逐步训练技术,进一步提高了性能和稳定性,代表了文本到视频生成技术的最新进展。智谱AI在8月27日开源 CogVideoX 系列更大的模型 CogVideoX-5B。CogVideoX-5B与之前的CogVideoX-2B相比,不仅在视频生成质量上有显著提升,还在模型训练和推理效率上取得了重要进展。
CogVideo主要功能
- 文本到视频生成:根据文本提示生成视频内容,能够理解和转化文本描述为动态视觉场景。
- 高质量视频输出:生成的视频具有高分辨率和丰富的动态细节,保持了与文本描述的一致性。
- 长时视频生成能力:能够生成长时间连贯视频,捕捉和表现复杂的动态变化。
- 多模态对齐:通过先进的技术手段,确保文本描述与生成的视频内容在语义上高度一致。
- 开源模型权重:部分模型权重已开源,便于研究社区进行进一步的研究和应用。
CogVideo技术原理
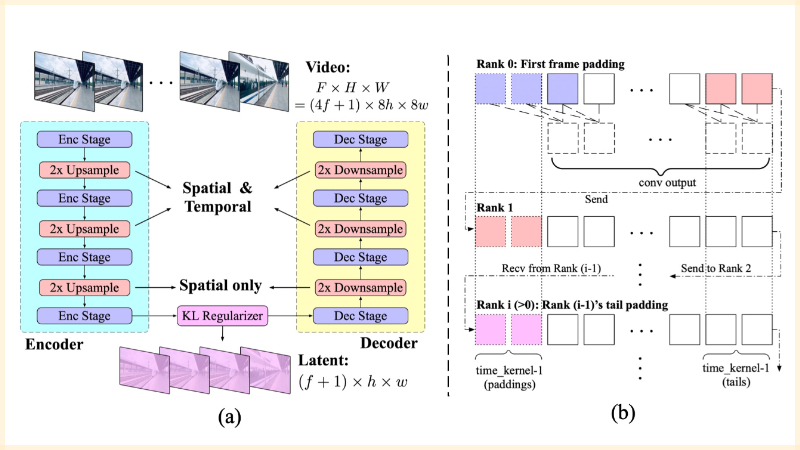
- 3D变分自编码器(3D VAE):用于压缩视频数据,减少计算成本,同时保持视频的空间和时间连续性。
- 专家变换器(Expert Transformer):一种特殊的变换器架构,用于处理和融合文本与视频数据,提高模态间的交互和对齐。
- 3D旋转位置编码(3D-RoPE):一种相对位置编码技术,用于捕捉视频数据中不同帧之间的空间和时间关系。
- 专家自适应层归一化(Expert Adaptive Layernorm):对不同模态的特征进行独立处理,优化特征空间的对齐。
- 混合时长训练(Frame Pack):允许模型在同一个批次中训练不同长度的视频,提高训练效率和模型泛化能力。
- 分辨率逐步训练:通过分阶段训练,先在低分辨率上训练模型以学习视频的大致结构,再在高分辨率上进行微调以捕捉细节。
- 显式均匀采样:在扩散过程中使用均匀的时间步长采样,以稳定训练过程并提高生成视频的一致性。
- 视频数据预处理:包括视频过滤和视频字幕生成,以确保训练数据的质量和相关性。
- 自动化和人类评估:使用自动化指标和人类评估相结合的方式,全面评估生成视频的质量。
CogVideo应用场景
- 电影和视频制作:快速生成电影预告片或动画短片,减少传统视频制作的时间和成本。
- 教育和培训:创建教育内容,如科学实验演示或历史事件重现,增强学习体验。
- 广告和营销:设计吸引人的广告视频,根据产品特点和营销策略快速生成创意视觉内容。
- 社交媒体内容:为社交媒体平台生成个性化或趋势性的视频内容,吸引观众关注。
- 虚拟现实和游戏:在虚拟现实环境或电子游戏中生成动态背景或故事情节,提升沉浸感。
- 新闻和报道:根据新闻稿或报道内容,快速生成新闻视频摘要或事件重演。
CogVideo项目入口
- 智谱清影官网:https://chatglm.cn/main/alltoolsdetail
- CogVideoX-2B模型地址:
- HuggingFace:https://huggingface.co/THUDM/CogVideoX-2b
- Modelscope:https://modelscope.cn/models/ZhipuAI/CogVideoX-2b
- CogVideoX-5B模型地址:
- GitHub代码库:https://github.com/THUDM/CogVideo
- arXiv技术论文:https://arxiv.org/pdf/2408.06072
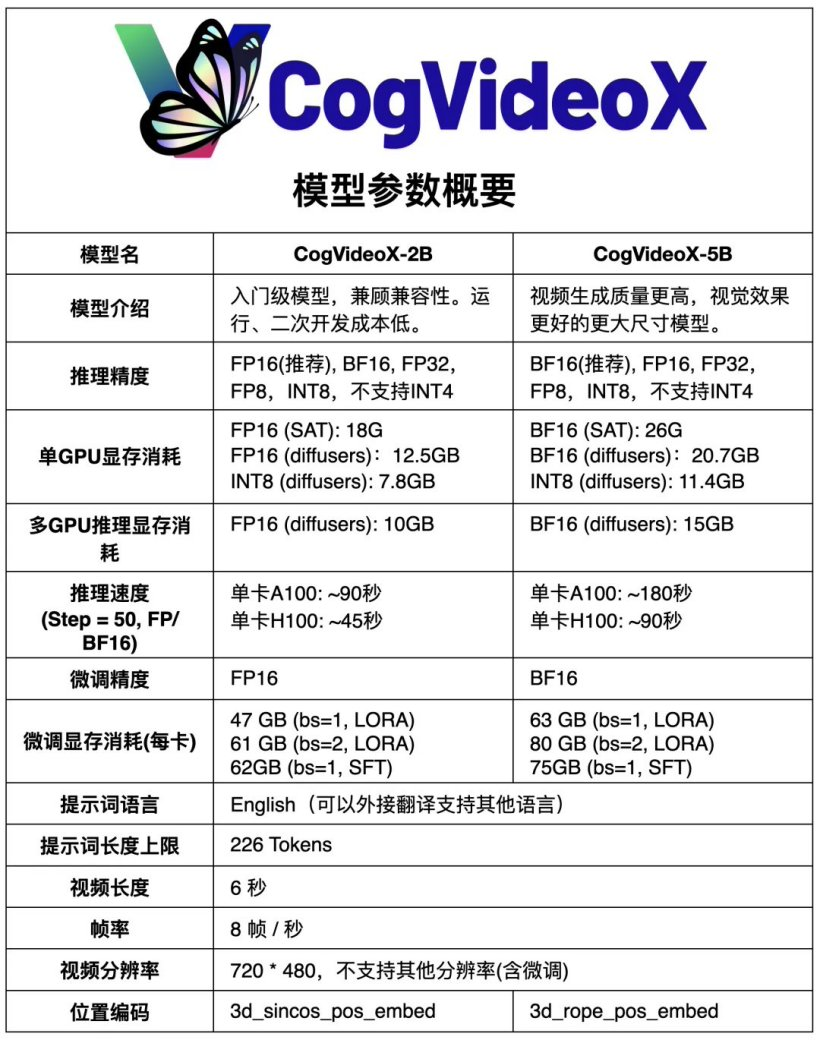
CogVideoX-2B和CogVideoX-5B两个模型的参数对比
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号