LSLM:具备边听边说能力的语音模型,实现实时的双向交流
LSLM简介
LSLM(Listening-while-Speaking Language Model)是由上海交通大学人工智能教育部重点实验室X-LANCE实验室与字节跳动公司联合开发的创新性端到端模型。该模型专为提升实时交互体验而设计,具备边听边说的能力,通过整合基于令牌的解码器仅文本到语音(TTS)模型和流式自监督学习(SSL)编码器,实现实时音频输入处理。LSLM通过三种融合策略——早期融合、中期融合和晚期融合——优化语音生成与实时互动之间的平衡,其中中期融合表现最为出色。该模型在嘈杂环境中展现出强大的鲁棒性,并能对未见说话者的多样化指令做出灵敏反应,推动了交互式语音对话系统向现实世界应用的更进一步发展。
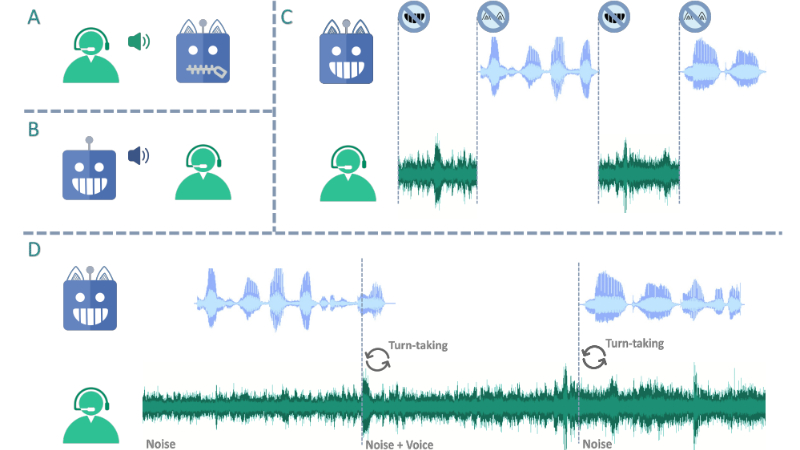
LSLM主要功能
- 实时双向交流:LSLM能够同时进行听和说的操作,实现实时的双向交流。
- 中断检测:模型能够检测到人类说话时的中断,并做出相应的响应,例如停止说话。
- 噪声鲁棒性:即使在嘈杂的环境中,LSLM也能准确识别和响应语音指令。
- 对未见说话者的敏感性:模型能够识别并响应来自未知说话者的指令,提高了交互的普适性。
LSLM技术原理
- 双通道设计:LSLM包含听和说两个独立的通道,分别处理音频输入和语音生成。
- 基于令牌的解码器仅TTS:使用基于令牌的解码器来生成语音,这种设计适合实时交互,因为它不需要等待整个序列的完成。
- 流式自监督学习(SSL)编码器:用于实时处理音频输入,将连续的音频信号转换为模型可以处理的离散令牌或连续嵌入。
- 多融合策略:
- 早期融合:在自回归预测之前将听和说通道的信息整合到输入嵌入中。
- 中期融合:在每个Transformer块中合并听和说通道的信息,除了说话通道的隐藏状态和位置嵌入外,还将听通道的信息添加到每个Transformer块的输入中。
- 晚期融合:在softmax操作前将通道信息合并到输出逻辑值中。
- 端到端训练:LSLM作为一个整体进行训练,优化了模型参数以同时提升语音生成和实时交互的能力。
- 自适应中断处理:模型通过增加中断令牌(IRQ)来提前终止当前的语音输出,以响应实时的语音输入。
- 上下文感知:模型在生成响应时考虑了上下文信息,提高了对话的连贯性和相关性。
LSLM应用场景
- 智能助手:作为智能手机或智能家居设备中的虚拟助手,能够实时响应用户的语音指令和问题。
- 客户服务:在客户服务中心,LSLM可以提供实时的语音交互服务,处理客户的咨询和请求。
- 语言翻译:在多语言环境中,LSLM可以实时翻译和交流,帮助跨语言沟通。
- 教育辅导:作为教育辅助工具,LSLM能够根据学生的提问实时提供语音反馈和解释。
- 医疗咨询:在医疗领域,LSLM可以提供实时的语音交互,帮助患者获取信息和指导。
- 会议记录:在商务会议中,LSLM可以实时记录会议内容,并根据讨论内容提供语音总结或提问。
LSLM项目入口
- arXiv研究论文:https://arxiv.org/abs/2408.02622
- Hugging Face模型:https://huggingface.co/papers/2408.02622
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号