Data-Juicer简介
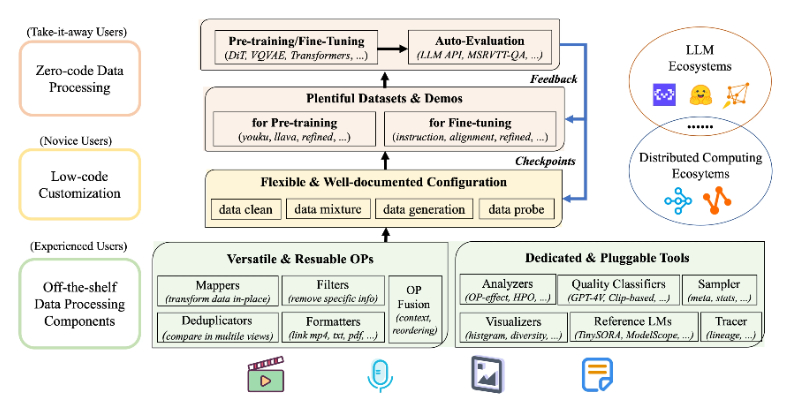
Data-Juicer 是由阿里推出的一款一站式大型语言模型(LLMs)数据处理系统。它通过提供超过50个内置操作符,支持用户灵活地组合和扩展,以生成多样化的数据配方。Data-Juicer 旨在通过其细粒度的流水线抽象和集成的可视化与自动评估功能,提高数据加工的效率和质量,从而显著提升 LLMs 的性能。此外,系统优化和与分布式计算生态系统的无缝集成,使得 Data-Juicer 在处理大规模数据集时表现出卓越的扩展性和效率。

Data-Juicer主要功能
- 多样化数据配方生成:能够高效地创建和探索不同类型的数据混合,以适应各种训练需求。
- 细粒度流水线抽象:提供超过50个内置操作符,用户可以自由组合和扩展,以构建数据配方。
- 可视化与自动评估:集成了可视化工具和自动评估功能,以便在数据加工后及时反馈模型性能。
- 灵活性与可定制性:支持从零代码处理到深度定制,满足不同层次用户的需求。
- 与LLM生态系统集成:优化并集成了大型语言模型训练、评估和分布式计算的生态系统。
- 性能提升:在多个基准测试中证明能显著提高模型性能,包括在特定评估中提高胜率和减少数据量需求
Data-Juicer技术原理
- 统一数据表示:使用 Huggingface-datasets 作为基础,将多种数据格式统一为具有嵌套访问支持的结构化格式。
- 多功能操作符(OPs):包括格式化器、映射器、过滤器和去重器,用于数据的清洗、编辑、过滤和去重。
- 操作符的组合性:设计了可组合的操作符,允许用户根据不同需求调整数据处理流程。
- 超参数优化(HPO):将 HPO 应用于数据加工过程,通过自动化工具快速找到最优的数据加工参数。
- 检查点和缓存机制:在数据加工过程中,使用检查点和缓存来提高效率和可靠性,减少重复计算。
- 交互式可视化:提供直观的数据跟踪和统计分析工具,帮助用户理解数据加工的影响。
- 系统优化:包括上下文管理、操作符融合和重排序,以减少冗余计算并提高执行效率。
- 分布式数据处理:与分布式计算框架集成,支持在多节点集群上加速数据处理和生成。
Data-Juicer应用场景
- 预训练数据准备:生成用于训练大型语言模型的大规模、多样化的数据集。
- 微调数据优化:为特定领域或任务定制和优化数据,以提高模型的微调效果。
- 数据清洗与去重:清洗原始数据集,去除噪声和重复项,提升数据质量。
- 多语言模型训练:处理和混合多种语言的数据,支持多语言模型的开发。
- 领域特定模型开发:针对特定行业或领域,如医疗、法律等,定制数据配方以训练专业模型。
- 模型性能评估:通过加工和评估数据,快速迭代模型训练,优化模型性能。
Data-Juicer项目入口
- GitHub代码库:https://github.com/modelscope/data-juicer
- arXiv研究论文:https://arxiv.org/abs/2309.02033
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号