LLaVA-OneVision简介
LLaVA-OneVision 是由字节跳动、南洋理工大学、香港中文大学和香港科技大学的专家团队共同研发的一系列先进大型多模态模型。这些模型通过整合数据、模型和视觉表示的深入见解,实现了在单图像、多图像以及视频场景中的卓越性能。它们不仅在多个计算机视觉基准测试中取得了突破性的成绩,还通过任务迁移和组合展现出了强大的跨场景能力。LLaVA-OneVision 的设计允许模型在不同视觉任务和数据类型之间灵活转换,为解决现实世界的视觉识别和理解问题提供了强大的工具,标志着人工智能在视觉任务处理方面迈出了重要的一步。

LLaVA-OneVision主要功能
- 多模态学习能力:能够同时处理单图像、多图像和视频场景,展现出强大的迁移学习能力。
- 任务迁移:模型能够将从图像学到的知识迁移到视频理解任务,实现跨模态的学习能力。
- 图表和表格理解:能够将对图表和表格的理解能力迁移到多图像场景中,实现图像内容的连贯解释。
- 交互式代理:作为代理角色,能够识别和交互 iPhone 屏幕截图,提供自动化任务的操作指令。
- 标记提示能力:在回答问题时能够引用图像中的标记,展示对细节的视觉内容的理解和描述能力。
- 视频创作提示生成:基于静态图像生成详细的视频创作提示,将图像到图像的语言编辑能力扩展到视频领域。
- 视频差异分析:能够分析具有相同起始帧但不同结尾的视频之间的差异,以及具有相似背景但不同前景对象的视频之间的差异。
- 多摄像机视频分析:在自动驾驶等多摄像机视频场景中进行分析和解释。
- 视频内容描述:提供视频内容中突出主题的详细描述。
LLaVA-OneVision技术原理
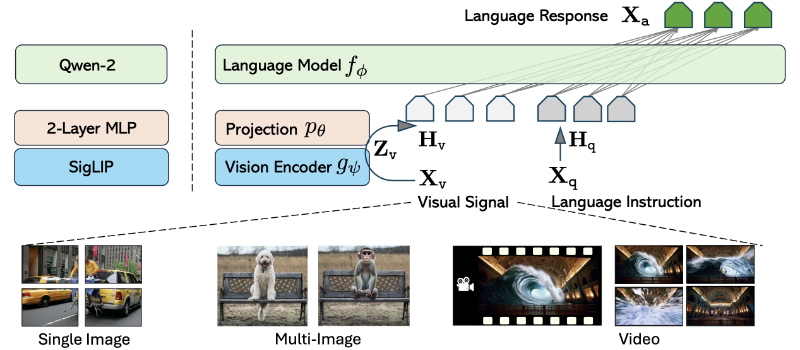
- 视觉表示策略:设计了在不同场景中视觉标记的最大数量相似,以确保平衡的表示,适应跨场景能力转移。
- 网络架构:展示了当前模型实例和扩展到更多视觉信号的 LLaVA 的一般形式,以适应不同的视觉任务。
- 数据和模型整合:基于 LLaVA-NeXT 博客系列中的数据、模型和视觉表示的深入见解,整合了这些要素来开发模型。
- 开源共享:通过开源训练代码、预训练模型检查点和数据集,促进社区的进一步开发和研究。
- 涌现能力:通过任务迁移和组合,模型展现出解决现实世界计算机视觉任务的新行为和能力。
- 跨场景理解:模型能够理解和描述由多个子视频组成的复杂视频内容,以及提供对视频内容中突出主题的详细描述。
- 视觉查询关联:模型能够关联图像和视频理解中的视觉查询,准确识别同一个体在不同图像和视频中的出现。
LLaVA-OneVision应用场景
- 自动驾驶:分析和解释多摄像机视频,为自动驾驶车辆提供环境感知能力。
- 视频编辑:基于静态图像生成视频创作提示,简化视频制作流程。
- 智能监控:通过视频差异分析,监控系统能够识别异常行为或事件。
- 医疗影像分析:利用图像理解能力,辅助医生分析医学影像资料。
- 社交媒体内容管理:自动标记和分类社交媒体上的图像和视频内容。
- 教育辅助:解释图表和表格,辅助学生更好地理解复杂概念。
LLaVA-OneVision项目入口
- 官方项目主页:https://llava-vl.github.io/blog/2024-08-05-llava-onevision/
- GitHub代码库:https://github.com/LLaVA-VL/LLaVA-NeXT
- arXiv研究论文:https://arxiv.org/abs/2408.03326
- Hugging Face模型:https://huggingface.co/lmms-lab
- 在线体验:https://llava-onevision.lmms-lab.com/
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号