Agent Q :具有规划和自我修复能力的新一代人工智能代理
Agent Q简介
Agent Q是由MultiOn公司和斯坦福大学联合开发的一款自主AI代理框架,旨在提升人工智能代理在复杂环境中的自主决策和推理能力。该技术框架通过结合蒙特卡洛树搜索(MCTS)和直接偏好优化(DPO)算法,使代理能够从成功和失败的交互中学习,显著提高了在多步骤推理任务中的表现。Agent Q在模拟电商环境WebShop和真实世界预订场景中进行了验证,显示出超越人类平均水平的性能,代表了自主AI代理在复杂决策制定方面的重大进步。
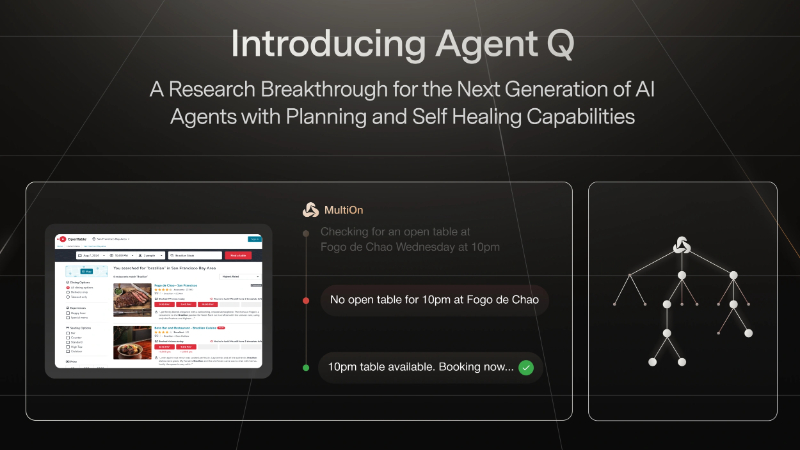
Agent Q主要功能
- 复杂推理能力:Agent Q能够在多步骤任务中进行复杂推理,处理诸如网页导航等动态环境中的决策问题。
- 自主学习与改进:通过自我批评机制和迭代微调,Agent Q能够从交互经验中学习,不断优化其策略。
- 蒙特卡洛树搜索(MCTS):使用MCTS来指导代理在网页中的探索和行动选择,平衡探索与利用。
- 直接偏好优化(DPO):利用DPO算法进行离线强化学习,从成功和不成功的轨迹中学习,提高代理性能。
- 零样本学习:Agent Q展示了出色的零样本学习能力,即使在没有接受过特定任务训练的情况下也能表现出色。
- 在线搜索能力:当配备在线搜索功能时,Agent Q能够访问和利用网络信息,进一步提升任务完成率。
Agent Q技术原理
- 引导式搜索:结合MCTS和自我批评机制,Agent Q在搜索过程中使用UCB1启发式方法来选择最优路径。
- 自我批评:代理在每个节点上使用AI反馈进行自我评估,提供中间奖励,帮助指导搜索步骤。
- 迭代微调:通过DPO算法对代理进行迭代微调,利用累积的偏好数据来优化策略。
- 离线数据使用:DPO算法允许使用完全离线数据进行训练,无需在线模型迭代,降低了训练成本和风险。
- 偏好对构建:在节点级别创建不同分支的偏好对,使用AI过程反馈奖励和探索分支的最终成功率进行评分。
- 多步骤问题优化:DPO目标函数扩展到多步骤代理问题,允许模型在与外部环境交互时进行优化。
- 模型反馈:使用基础LLM生成动作的反馈分数,通过模型自身对动作的有用性进行排名,以指导探索过程。
- 状态-动作值估计:结合MCTS的实证价值估计和基于AI模型排名的动作价值估计,来构建状态-动作值。
Agent Q应用场景
- 电子商务平台:Agent Q可以在模拟或真实的电子商务网站中进行商品搜索和交易预订,如WebShop环境。
- 在线预订服务:应用于OpenTable等在线预订平台,完成餐厅订位等任务。
- 代码和软件工程:在编程环境中,Agent Q可以辅助代码生成和软件工程任务,解决实际的编程问题。
- 设备控制:Agent Q可以集成到智能家居或办公设备中,进行设备控制和管理。
- 网页应用交互:在需要与网页应用进行复杂交互的场景中,Agent Q可以自动化用户界面操作。
- 信息检索:Agent Q能够执行网络搜索任务,从大量在线信息中检索和整理所需数据。
Agent Q项目入口
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...










一站式AI信息服务平台:AI工具大全、AI每日快讯、AI项目库、AI融资快报、AI研究报告、AI教程、AI副业、AI考证等。助您全面系统了解AI、使用AI


 粤公网安备44011102483711号
粤公网安备44011102483711号